目录
嵌入式笔记
RTOS
内核态,用户态的区别
区别:运行级别,是否可以操作硬件
用户态->内核态:系统调用、异常、外围设备中断
进程、线程
概述区别
- 地址
- 进程是资源分配的最小单位,线程是CPU调度的最小单位,进程有独立分配的内存空间,线程共享进程空间
- 真正在cpu上运行的是线程
- 开销
- 进程切换开销大,线程轻量级
- 并发性
- 进程并发性差
- 崩溃
-
线程的崩溃不一定导致进程的崩溃
-
线程在进程下行进(单纯的车厢无法运行)
-
一个进程可以包含多个线程(一辆火车可以有多个车厢)
-
不同进程间数据很难共享(一辆火车上的乘客很难换到另外一辆火车,比如站点换乘)
-
同一进程下不同线程间数据很易共享(A车厢换到B车厢很容易)
-
进程要比线程消耗更多的计算机资源(采用多列火车相比多个车厢更耗资源)
-
进程间不会相互影响,一个线程挂掉将导致整个进程挂掉(一列火车不会影响另外一列火车,但如果一列火车上中间的一节车厢着火了,将影响到所有车厢)
-
进程可以拓展到多机,进程最多适合多核(不同火车可以开在多个轨道上,同一火车的车厢不能在行进的不同的轨道上)
-
进程使用的内存地址可以上锁,即一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存。(比如洗手间)-"互斥锁"
-
进程使用的内存地址可以限定使用量(比如火车上的餐厅,最多只允许多少人进入,如果满了需要在门口等,等有人出来了才能进去)-“信号量”
- 资源占用:每个进程都有独立的内存空间,包括代码、数据、堆栈等,而线程共享所属进程的内存空间。因此,在创建、切换和销毁进程时,涉及到较大的资源开销,而线程切换和创建时的开销较小。
- 并发性:进程是独立运行的执行单位,多个进程之间可以并发,每个进程都有自己的执行状态、程序计数器和堆栈指针等。线程是进程内的执行流,多个线程共享进程的资源,在同一进程中的多个线程可以并发执行。
- 通信和同步:进程间的通信比较复杂,需要通过特定的机制(如管道、消息队列、等)进行数据的传递和共享。而线程之间共享进程的资源,通信相对容易,可以直接访问共享的内存变量。在多线程编程中,线程之间需要通过同步机制(如锁、信号量、条件变量等)来保证数据的一致性和正确性。
- 安全性:由于线程共享进程的资源,多个线程之间对共享数据的访问需要进行同步控制,否则可能会出现竞争条件(Race Condition)和数据不一致的问题。相比之下,进程间的数据相对独立,每个进程拥有独立的内存空间,更加安全。
什么时候使用进程与线程
多进程:
- 优点:进程独立,不影响主程序稳定性,可多CPU运行
- 缺点:逻辑复杂,IPC通信困难,调度开销大
多线程:
- 优点:线程间通信方便,资源开销小,程序逻辑简单
- 缺点:线程间独立互斥困难,线程崩溃影响进程
选择:频繁创建的用线程,CPU密集用进程,IO密集用线程
总结:安全稳定选进程,快速频繁选线程
为什么进程切换比线程切换慢
所需保存的上下文不同
- 进程切换涉及到页表的切换,页表的切换实质上导致TLB的缓存全部失效,这些寄存器里的内容需要全部重写。而线程切换无需经历此步骤。
- 线程切换涉及到线程栈
进程可以创建线程数量
(可用虚拟空间和线程的栈的大小共同决定)一个进程可用虚拟空间是2G,默认情况下,线程的栈的大小是1MB,所以理论上最多只能创建2048个线程
TCB与PCB
线程控制块与进程控制块
PCB:
- 进程ID
- 进程状态寄存器
- 锁、信号量等同步机制与上下文信息
- 进程优先级、等待时间等其他内存
- 内存空间范围
- 线程状态
- 文件描述符
TCB:
- 线程ID
- 线程状态寄存器
- 锁、信号量等同步机制与上下文信息
- 线程优先级
进程上下文切换保存的数据
PCB、CPU通用寄存器、浮点寄存器、用户栈、内核数据结构(页表、进程表、文件表)
线程上下文切换保存的内容
- TCB信息
- 寄存器状态:如R0-R3、SP、LR、PC等
- 程序状态字:如程序处于中断、用户态、内核态等标志位
- 堆栈:线程执行期间所用的变量等信息
- 浮点FPU寄存器
TLB(Translation Lookaside Buffer)
页表的cache,也称为快表,属于MMU的一部分
TLB、页表、Cache、主存之间的访问关系
首先,程序员应该给出一个逻辑地址。通过逻辑地址去查询TLB和页表(一般是同时查询,TLB是页表的子集,所以TLB命中,页表一定命中;但是页表命中,TLB不一定命中),以确定该数据是否在主存中。因为只要TLB和页表命中,该数据就一定被调入主存。如果TLB和页表都不命中,则代表该数据就不在主存,所以必定会导致Cache访问不命中。现在,假设该数据在主存中,那么Cache也不一定会命中,因为Cache里面的数据仅仅是主存的一小部分。
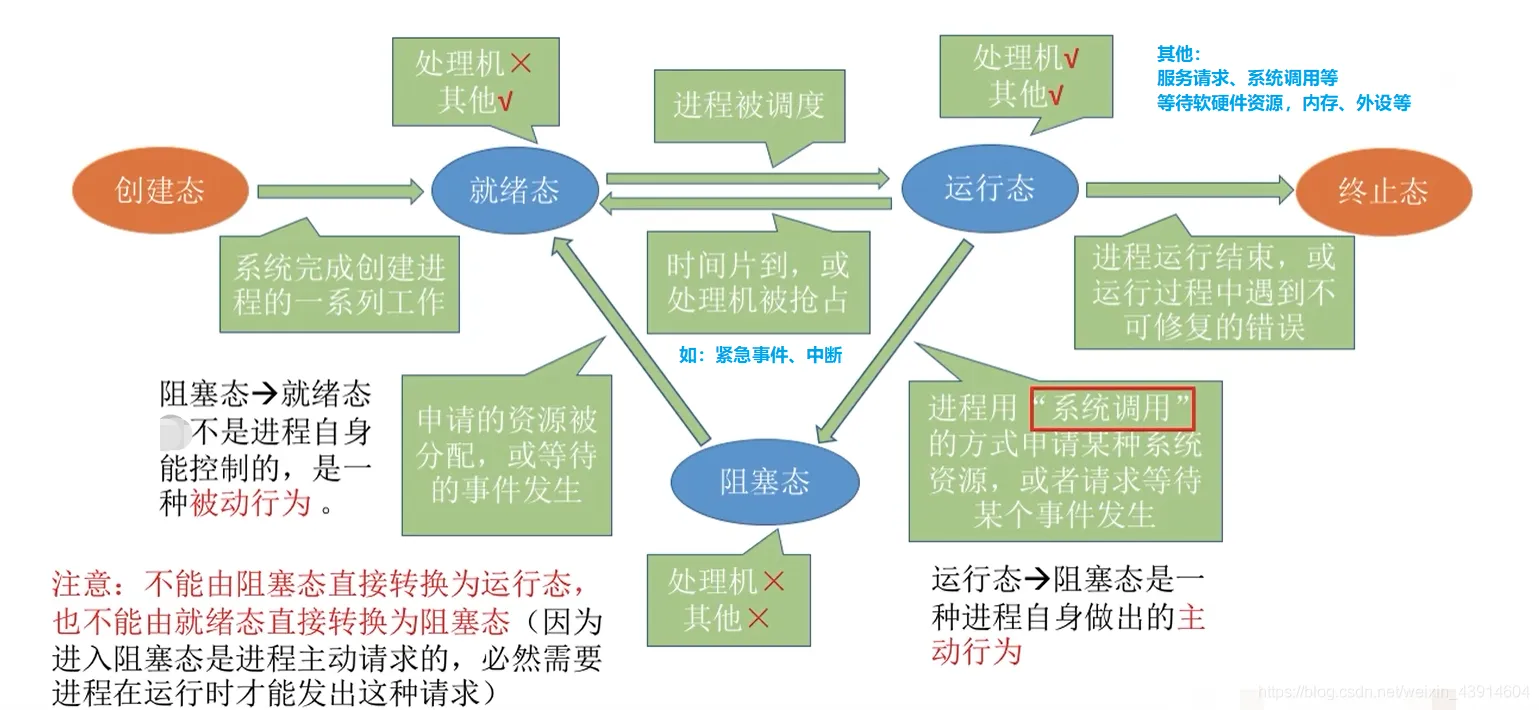
任务调度
父子进程、僵尸、孤儿
子进程:父进程执行fork()系统调用,复制出一个和自身基本一致的进程为子进程,随后执行exec()系统调用,父进程执行其他任务
孤儿进程: 父进程生成子进程,但是父进程比子进程先结束,系统在子进程结束后回收资源
僵尸进程:子进程已经退出,但是没有父进程回收它的资源
fork():建立一个新的子进程。其子进程会复制父进程的数据与堆栈空间,并继承已打开的文件代码、工作目录和资源限制等
死锁的原因、条件
两个或两个以上的进程在,因争夺资源而造成的一种互相等待的现象
原因:资源不足、分配不当、推进顺序不合适
条件:
(1) 互斥条件:一个资源每次只能被一个进程使用。 (2) 不剥夺条件:进程已获得的资源,在末释放前,不能强行剥夺。 (3) 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。 (4) 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
解除与预防:打破上述一个条件即可
OS中原子操作是如何实现的
底层通过关闭中断或原子指令(硬件支持)的方式
Linux通过原子指令
进程间通信
进程有独立的地址空间,线程公用地址空间。
| 类别 | 信号 | 信号量 | 消息队列 | 管道 | 共享内存 | socket |
|---|---|---|---|---|---|---|
| 描述 | 软中断 | 计数器,同步互斥 | 消息链表 | 无名管道(父子进程间通信)+有名管道(FIFO文件) | 将同一块内存映射到不同进程(最快最有效) | 面向网络的通信 |
| 流向 | 单向 | 单向 | 双向 |
事件不是进程间通信的方式
有名管道、无名管道
进程间通信(IPC)是指操作系统中不同进程之间进行数据交换和共享的机制。无名管道和有名管道都是常见的进程间通信方式。
- 无名管道(Unnamed Pipe):
- 无名管道是一种半双工的、只能在具有公共祖先的进程之间使用的通信机制。
- 创建无名管道时,操作系统会为其分配一个读端和一个写端。
- 数据通过管道在进程之间单向流动,一端写入数据,另一端从中读取。
- 无名管道通常用于父子进程之间的通信,可以通过fork()系统调用创建。
- 无名管道只能用于有亲缘关系的进程之间的通信,无法被其他进程访问。
- 有名管道(Named Pipe):
- 有名管道也称为FIFO(First In, First Out),它提供了一种在无亲缘关系的进程之间进行通信的方法。
- 有名管道通过在文件系统中创建一个特殊类型的文件来实现,该文件具有独立的文件名。
- 不同进程可以通过打开该文件并对其进行读写来进行通信。
- 有名管道允许多个进程同时向其中写入数据或者从中读取数据。
- 有名管道可以被许多不相关的进程使用,提供了一种灵活的进程间通信方式。
无名管道和有名管道都是通过读写文件描述符来进行通信的。它们在实现上有所差异,适用于不同的场景和需求。
线程间通信
进程有独立的地址空间,线程公用地址空间。
信号、互斥锁、读写锁、自旋锁、条件变量、信号量
线程间无需特别的手段进行通信,因为线程间可以共享一份全局内存区域,其中包括初始化数据段、未初始化数据段,以及堆内存段等,所以线程之间可以方便、快速地共享信息。只需要将数据复制到共享(全局或堆)变量中即可。不过,要考虑线程的同步和互斥,应用到的技术有:
- 信号 Linux 中使用 pthread_kill() 函数对线程发信号。
- 互斥锁确保同一时间只能有一个线程访问共享资源,当锁被占用时试图对其加锁的线程都进入阻塞状态(释放 CPU 资源使其由运行状态进入等待状态),当锁释放时哪个等待线程能获得该锁取决于内核的调度。
- 读写锁当以写模式加锁而处于写状态时任何试图加锁的线程(不论是读或写)都阻塞,当以读状态模式加锁而处于读状态时“读”线程不阻塞,“写”线程阻塞。读模式共享,写模式互斥。
- 自旋锁上锁受阻时线程不阻塞而是在循环中轮询查看能否获得该锁,没有线程的切换因而没有切换开销,不过对 CPU 的霸占会导致 CPU 资源的浪费。 所以自旋锁适用于并行结构(多个处理器)或者适用于锁被持有时间短而不希望在线程切换产生开销的情况。
- 条件变量 条件变量可以以原子的方式阻塞进程,直到某个特定条件为真为止。对条件的测试是在互斥锁的保护下进行的,条件变量始终与互斥锁一起使用。
- 信号量 信号量实际上是一个非负的整数计数器,用来实现对公共资源的控制。在公共资源增加的时候,信号量就增加;公共资源减少的时候,信号量就减少;只有当信号量的值大于0的时候,才能访问信号量所代表的公共资源。
条件变量condition variable
c++11中,当条件不满足时,相关线程被一直阻塞,直到某种条件出现,这些线程才会被唤醒
- 线程的阻塞是通过成员函数wait()/wait_for()和wait_until()实现
- 线程唤醒是通过函数notify_all()和notify_one()实现
虚假唤醒:在正常情况下,wait类型函数返回时要么是因为被唤醒,要么是因为超时才返回,但是在实际中发现,因此操作系统的原因,wait类型在不满足条件时,它也会返回,这就导致了虚假唤醒。
c++if (不满足xxx条件) {
//没有虚假唤醒,wait函数可以一直等待,直到被唤醒或者超时,没有问题。
//但实际中却存在虚假唤醒,导致假设不成立,wait不会继续等待,跳出if语句,
//提前执行其他代码,流程异常
wait();
}
//其他代码
...
// 实际使用:
while (!(xxx条件) )
{
//虚假唤醒发生,由于while循环,再次检查条件是否满足,
//否则继续等待,解决虚假唤醒
wait();
}
//其他代码
....
案例:生产者消费者模式
c++#include <mutex>
#include <deque>
#include <iostream>
#include <thread>
#include <condition_variable>
class PCModle {
public:
PCModle() : work_(true), max_num(30), next_index(0) {
}
void producer_thread() {
while (work_) {
std::this_thread::sleep_for(std::chrono::milliseconds(500));
//加锁
std::unique_lock<std::mutex> lk(cvMutex);
//当队列未满时,继续添加数据
cv.wait(lk, [this]() { return this->data_deque.size() <= this->max_num; });
next_index++;
data_deque.push_back(next_index);
std::cout << "producer " << next_index << ", queue size: " << data_deque.size() << std::endl;
//唤醒其他线程
cv.notify_all();
//自动释放锁
}
}
void consumer_thread() {
while (work_) {
//加锁
std::unique_lock<std::mutex> lk(cvMutex);
//检测条件是否达成
cv.wait(lk, [this] { return !this->data_deque.empty(); });
//互斥操作,消息数据
int data = data_deque.front();
data_deque.pop_front();
std::cout << "consumer " << data << ", deque size: " << data_deque.size() << std::endl;
//唤醒其他线程
cv.notify_all();
//自动释放锁
}
}
private:
bool work_;
std::mutex cvMutex;
std::condition_variable cv;
//缓存区
std::deque<int> data_deque;
//缓存区最大数目
size_t max_num;
//数据
int next_index;
};
int main() {
PCModle obj;
std::thread ProducerThread = std::thread(&PCModle::producer_thread, &obj);
std::thread ConsumerThread = std::thread(&PCModle::consumer_thread, &obj);
ProducerThread.join();
ConsumerThread.join();
return 0;
}
共享内存
共享内存是进程间通信的一种方式。不同进程之间共享的内存通常为同一段物理内存,进程可以将同一段物理内存连接到他们自己的地址空间中,所有的进程都可以访问共享内存中的地址。如果某个进程向共享内存写入数据,所做的改动将立即影响到可以访问同一段共享内存的任何其他进程。
- 优点:访问高效,通信时无需内核接入避免不必要的复制
- 缺点:没有同步机制,需要手动设计
关闭中断的方式
Cortex-M3和M4中断屏蔽寄存器有三种
- PRIMASK
- FAULTMASK
- BASEPRI
- PRIMASK寄存器设置为1后,关闭所有中断和除了HardFault异常外的所有其他异常,只有NMI、Reset和HardFault可以得到响应。
assemblyCPSIE I; // 清除PRIMASK(使能中断) CPSID I; // 设置PRIMASK(禁止中断)
- FAULTMASK寄存器会把异常的优先级提升到-1,设置为1后关闭所有中断和异常,包括HardFault异常,只有NMI和Reset可以得到响应。
assenblyCPSIE F; // 清除FAULTMASK CPSID F; // 设置FAULTMASK
- BASEPRI寄存器可以屏蔽低于某一个阈值的中断。
设置为n后,屏蔽所有优先级数值大于等于n的中断和异常。Cortex-M的优先级数值越大其优先级越低。
RT-Thread关闭中断
采用汇编代码实现,上述第一种关闭中断的方式,屏蔽全部中断,仅响应HardFault、NMI、Reset
rt_hw_interrupt_disable
assembly;/* ; * rt_base_t rt_hw_interrupt_disable(); ; */ rt_hw_interrupt_disable PROC EXPORT rt_hw_interrupt_disable MRS r0, PRIMASK CPSID I BX LR ENDP
FreeRTOS关闭中断
c#define configLIBRARY_MAX_SYSCALL_INTERRUPT_PRIORITY // 此宏用来设置FreeRTOS系统可管理的最大优先级,也就是BASEPRI寄存器中存放的阈值。
// 关中断
// 向basepri中写入configMAX_SYSCALL_INTERRUPT_PRIORITY,
// 表明优先级低于configMAX_SYSCALL_INTERRUPT_PRIORITY的中断都会被屏蔽
static portFORCE_INLINE void vPortRaiseBASEPRI( void )
{
uint32_t ulNewBASEPRI = configMAX_SYSCALL_INTERRUPT_PRIORITY;
__asm
{
msr basepri, ulNewBASEPRI
dsb
isb
}
}
RT-Thread rt_enter_critical()和rt_hw_interrupt_disable()区别
crt_enter_critical() //禁用调度器,不关闭中断,可嵌套调用,深度65535
rt_hw_interrupt_disable() // 关闭中断,可嵌套调用
FreeRTOS taskENTER_CRITICAL和taskDISABLE_INTERRUPTS区别
cvTaskSuspendAll() // 挂起调度器。不关中断,属于 FreeRTOS 层面,不直接依赖具体的硬件,可嵌套调用
taskENTER_CRITICAL // 支持嵌套调用,底层为关闭部分中断,有引用计数
taskDISABLE_INTERRUPTS // 关闭中断,不支持嵌套,实现方式为配置BASEPRI寄存器,屏蔽某些中断
在下面例子中,调用funcA函数后,再执行完funcB函数后中断就会被打开,从而导致funcC()函数不会被保护。而若使用taskENTER_CRITICAL和taskEXIT_CRITICAL则不会出现这种情况。
c在临界区ENTER/EXIT内流程如下:
ENTER
/* 中断DISABLE */
ENTER
EXIT
/* 此时中断仍然DISABLE */
EXIT
/* 释放所有的临界区,现在才会中断ENABLE*/
但在中断DISABLE内流程则是如下:
DISABLE
/* 现在是中断DISABLE */
DISABLE
ENABLE
/* 即使中断DISABLE了两次,中断现在也会重新使能 */
ENABLE
void funcA()
{
taskDISABLE_INTERRUPT(); //关中断
funcB();//调用函数funcB
funcC();//调用函数funcC
taskENABLE_INTERRUPTS();//开中断
}
void funcB()
{
taskDISABLE_INTERRUPTS();//关中断
执行代码
taskENABLE_INTERRUPTS();//开中断
}
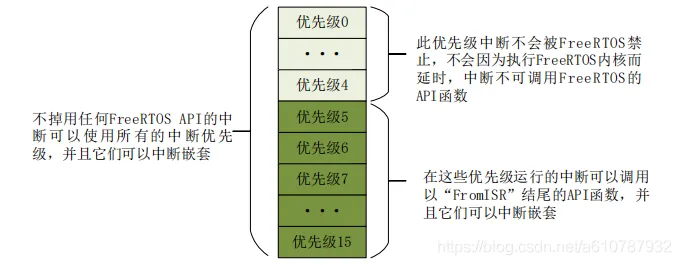
FreeFTOS中断优先级设置
设置FreeRTOS系统可管理的最大优先级,也就是高于5的优先级(小于5的优先级),FreeRTOS不管。
c#define configLIBRARY_LOWEST_INTERRUPT_PRIORITY 15 //中断最低优先级(0-15)
#define configLIBRARY_MAX_SYSCALL_INTERRUPT_PRIORITY 5 //系统可管理的最高中断优先级
临界区
访问公共资源的程序片段,并不是一种通信方式。
进入临界区的两种方式
ctaskENTER_CRITICAL();
{
.............// 临界区,关闭中断
}
taskEXIT_CRITICAL();
vTaskSuspendAll();
{
.............// 临界区,仅关闭调度器,但响应中断
}
xTaskResumeAll();
互斥锁Mutex、自旋锁Spin
当加锁失败时,互斥锁用「线程切换」来应对,自旋锁则用「忙等待」来应对
互斥锁:Mutex,独占锁,谁上锁谁有权释放,申请上锁失败后阻塞,不能在中断中调用
自旋锁:Spinlock:申请上锁失败后,一直判断是否上锁成功,消耗CPU资源,可在中断中调用
临界区与锁的对比
互斥锁与临界区的作用非常相似,但互斥锁(mutex)是可以命名的,也就是说它可以跨越进程使用。所以创建互斥锁需要的资源更多,所以如果只为了在进程内部使用的话使用临界区会带来速度上的优势并能够减少资源占用量。因为互斥锁是跨进程的互斥锁一旦被创建,就可以通过名字打开它
临界区是一种轻量级的同步机制,与互斥和事件这些内核同步对象相比,临界区是用户态下的对象,即只能在同一进程中实现线程互斥。因无需在用户态和核心态之间切换,所以工作效率比较互斥来说要高很多。
| 使用场景 | 操作权限 | |
|---|---|---|
| 临界区 | 一个进程下不同线程间 | 用户态,轻量级,快 |
| 互斥锁 | 进程间或线程间 | 内核态,切换,慢 |
阻塞与非阻塞区别
阻塞:条件不满足时等待,进入阻塞态直到条件满足被唤醒
非阻塞:条件不满足时立刻返回,继续执行其他任务
RTOS为何不用malloc和free
- 实现复杂,占用空间较多
- 并非线程安全操作
- 每次调用执行时间不确定
- 内存碎片化
- 不同编译器适配复杂
- 难以调试
FreeRTOS内存管理算法
heap_1~5中除了heap_3分配在堆上,其余算法在bss段开辟静态空间进行管理
c// 定义内存堆的大小
#define configTOTAL_HEAP_SIZE (8 * 1024) // 8KB
// 全局变量 "uc_heap" 的定义
static uint8_t ucHeap[configTOTAL_HEAP_SIZE];
uint8_t *ucHeap = ucHeap;
FreeRTOS笔记(六):五种内存管理详解_CodeDog_wang的博客-CSDN博客
FreeRTOS系列-- heap_4.c内存管理分析_为成功找方法的博客-CSDN博客
| 类别 | 优点 | 缺点 |
|---|---|---|
| heap_1 | 时间确定 | 只分配,不回收 |
| heap_2 | 最佳匹配 | 回收但不合并、时间不确定 |
| heap_3 | 使用标准malloc、free | 代码量大、线程不安全、时间不确定 |
| heap_4 | 最佳匹配、合并相邻 | 时间不确定 |
| heap_5 | 支持多段不连续RAM | 时间不确定 |
- heap_1
- 只分配不回收,不合并空闲区块
- heap_2
- 使用最佳拟合算法分配
- 回收,但不合并,有碎片
- heap_3
- 使用标准库malloc()和free()函数
- heap的大小由链接器配置定义(启动文件定义)
- heap_4
- 使用first fit算法来分配内存
- 合并相邻的空闲内存块
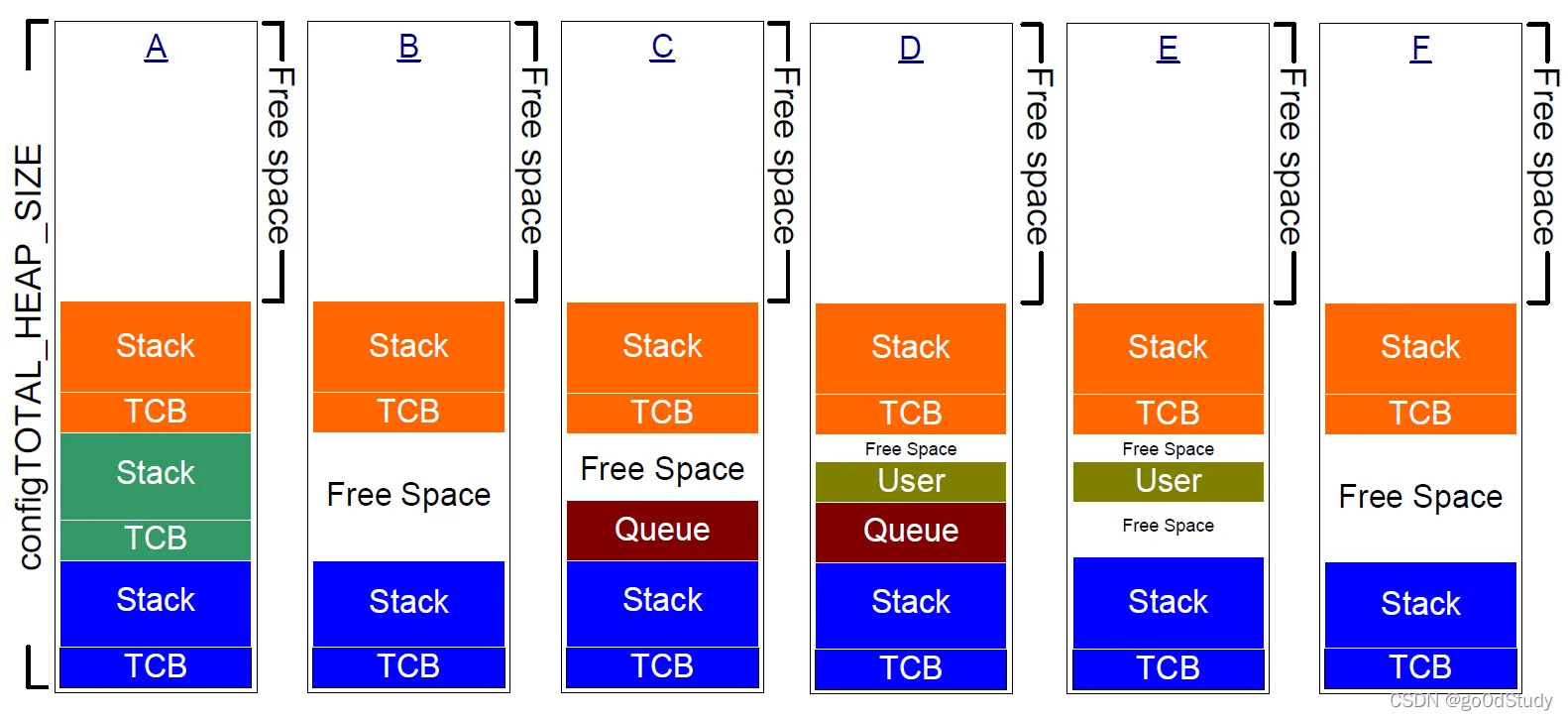
- heap_5
在heap_4的基础上,可以从多个独立的内存空间分配内存
内存池
内存池是一种用于管理和分配内存的技术。它被用于解决频繁地申请和释放内存带来的性能问题。
在传统的内存管理中,当需要使用内存时,通常会通过内存分配函数(如malloc)来动态申请一块内存空间。而释放内存时,则会调用相应的内存释放函数(如free)来释放内存。这种动态的内存分配和释放操作在频繁进行时,会产生很多开销,包括内存管理开销和内存碎片问题。
而内存池就是为了解决这个问题而设计的。它事先申请一定大小的内存空间,并将其划分成多个固定大小的块,形成一个池子。当需要使用内存时,直接从内存池中分配一个可用的块,而不是频繁地调用内存分配函数。在释放内存时,将内存块归还给内存池,而不是调用内存释放函数。
使用内存池的好处是可以降低内存碎片问题,减少动态内存分配和释放的开销。通过一次性申请和释放内存块,可以提高内存分配和释放的效率,从而提升程序性能。此外,内存池还可以提供内存分配的可预测性,避免因动态内存分配造成的不确定性和性能抖动。
RT-Thread内存管理算法
RT-T开辟静态数组的方式管理内存
c#define RT_HEAP_SIZE 6*1024
/* 从内部SRAM申请一块静态内存来作为内存堆使用 */
static uint32_t rt_heap[RT_HEAP_SIZE]; // heap default size: 24K(1024 * 4 * 6)
| 算法 | 文件 | 说明 | 例子 |
|---|---|---|---|
| mem小内存 | mem.c | 2MB以内小内存设备 | 一个瓜--吃多少切多少 |
| slab大内存 | slab.c | 大内存设备,内存池管理 | 一个瓜--已经切好大小--拿对应的 |
| memheap多内存 | memheap.c | 多个内存设备进行合并 | 多个瓜--吃完一个拿下一个 |
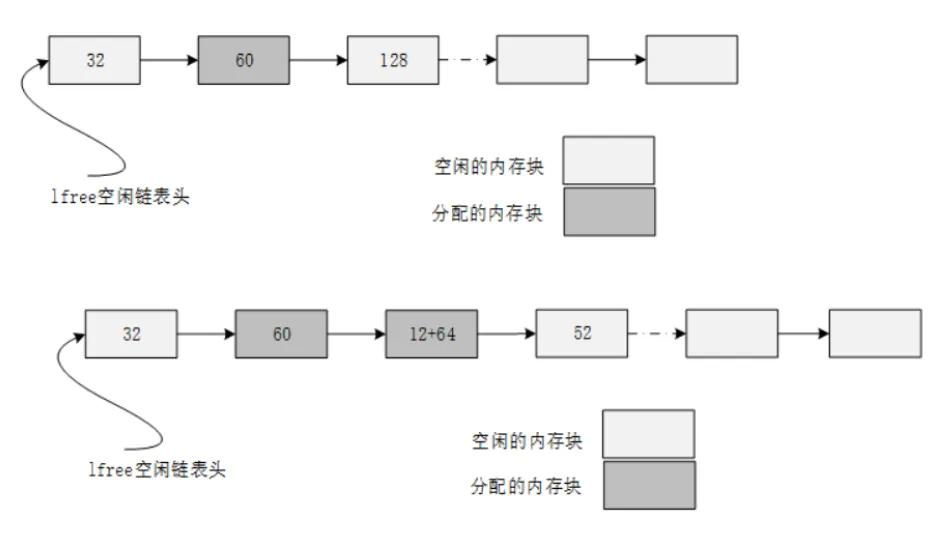
- mem小内存管理算法:heap_4
采用链表组织,每个表项包含{magic(是否被非法改写),used(是否被使用),next(指针域),prev(指针域)}
分配64 Bye内存的操作:从表头开始,寻找可用空间进行分配(表头占用3*4 Byte)
释放的操作:更改used表项,查看前后是否为空闲,如有进行合并为大内存块
-
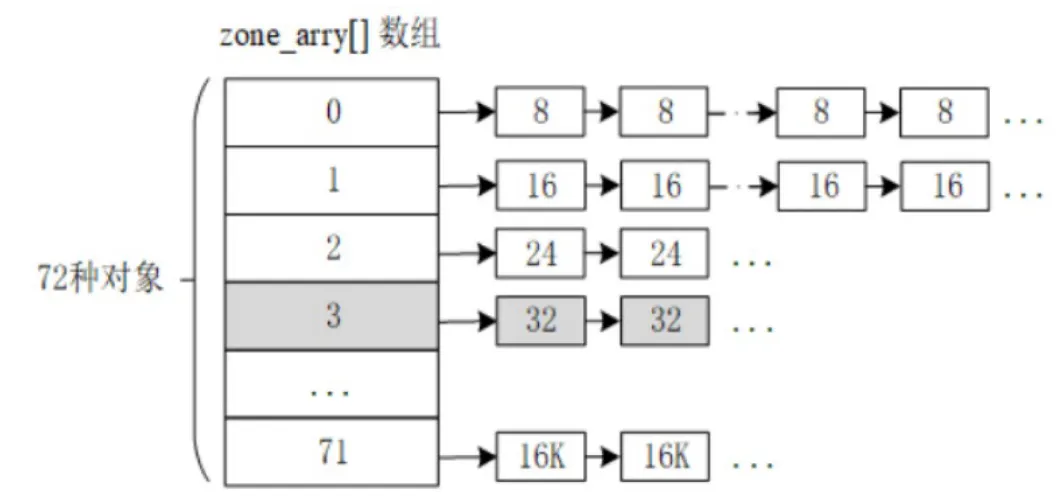
slab大内存管理算法:内存池
为避免频繁分配释放,提前将内存分块
-
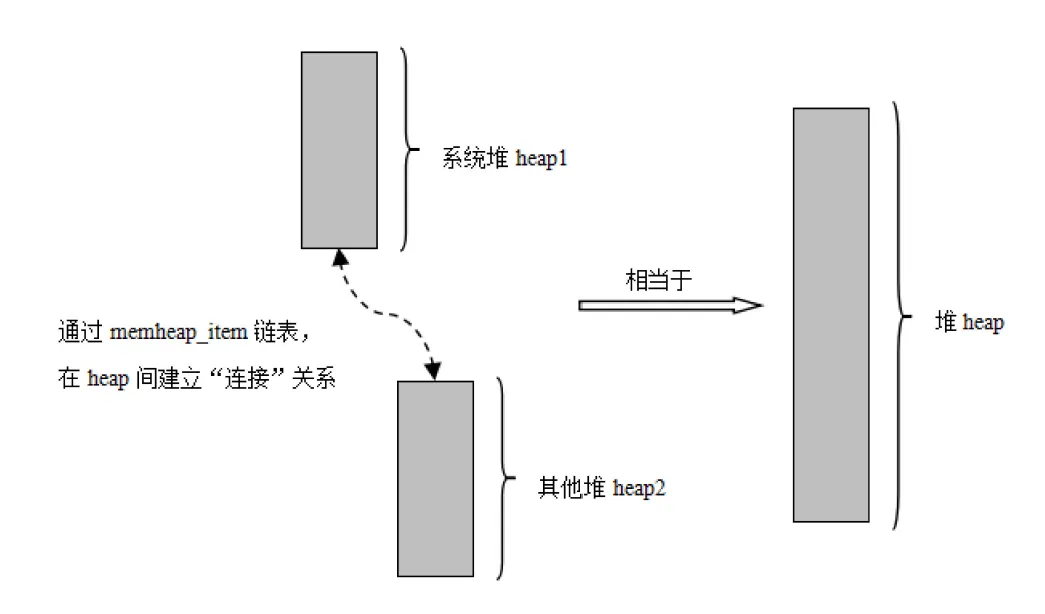
memheap内存管理算法:heap_5
将多个不连续的内存地址进行合并拼接

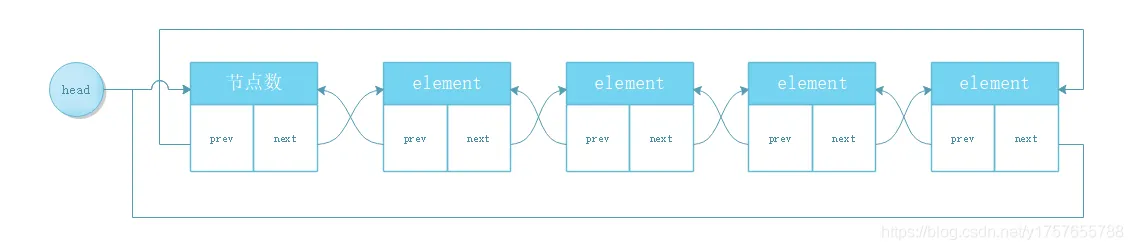
RT-Thread 链表
普通双向循环链表(针对每一个数据结构固定的节点进行操作)
RTT中双向循环链表(数据结构不固定)
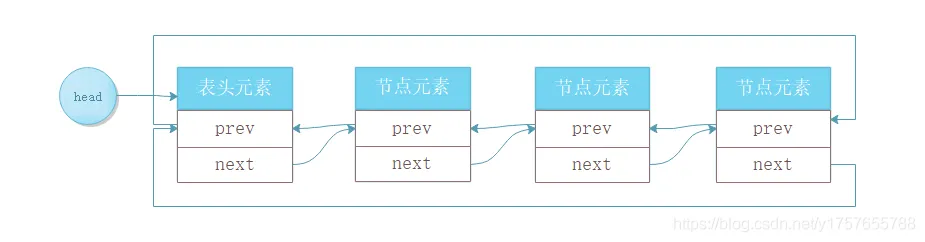
RTT中链表不依赖于节点数据类型,其指针域指向下一个指针域(插入的元素可以为不同类型),
指定节点前插入:
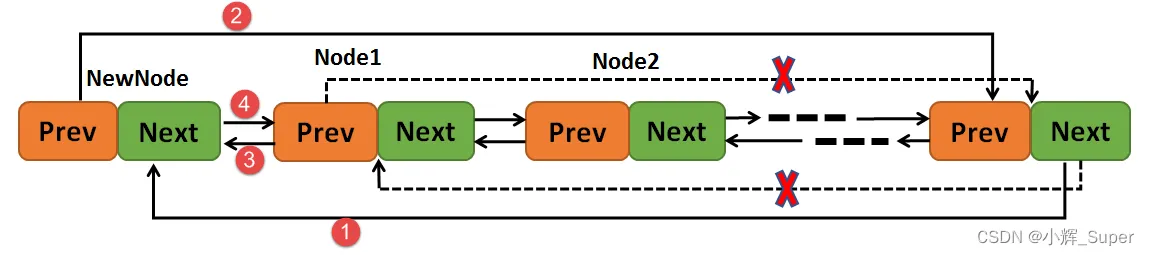
crt_inline void rt_list_insert_before(rt_list_t *l, rt_list_t *n)
{
l->prev->next = n;
n->prev = l->prev;
l->prev = n;
n->next = l;
}
指定节点后插入:
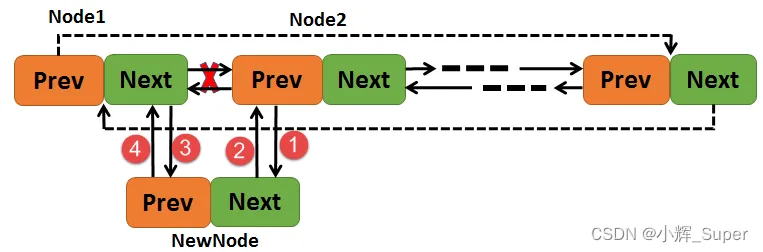
crt_inline void rt_list_insert_after(rt_list_t *l, rt_list_t *n)
{
l->next->prev = n;
n->next = l->next;
l->next = n;
n->prev = l;
}
删除节点:
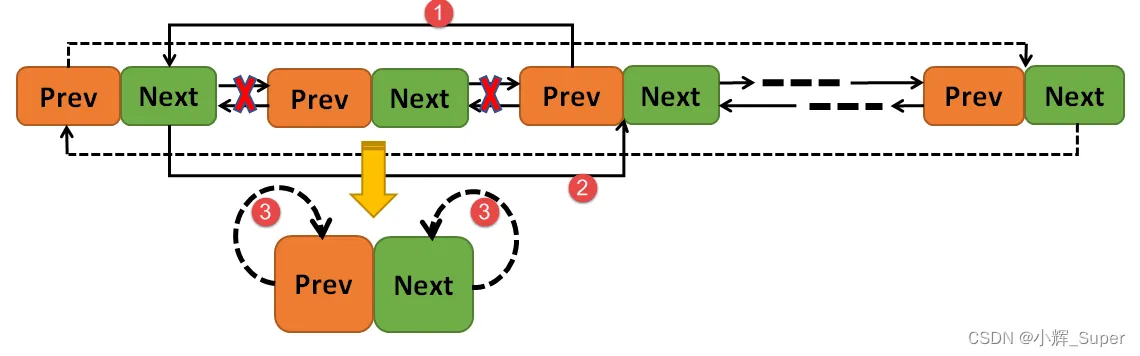
crt_inline void rt_list_remove(rt_list_t *n)
{
n->next->prev = n->prev;
n->prev->next = n->next;
n->next = n->prev = n;
}
节点元素的访问:
节点中,指针域的存放位置不确定,因此需要一种宏定义,从指针域寻找对应的结构体元素(通过rt_list_t成员的地址访问节点中的其他元素)
既然rt_list_t成员是存放在节点中部或是尾部,且不同类型的节点rt_list_t成员位置还不一样,那在遍历整个链表时,获得的是后继节点(前驱节点)的rt_list_t成员的地址,那如何根据rt_list_t成员的地址访问节点中其他元素。
尽管不同类型节点中rt_list_t成员位置不定,但是在确定类型节点中,rt_list_t成员的偏移是固定的,在获取rt_list_t成员地址的情况下,计算出rt_list_t成员在该节点中的偏移,即(rt_list_t成员地址)-(rt_list_t成员偏移)=节点起始地址。关键在于如何计算不同类型节点中rt_list_t成员偏移。RT-Thread中给出的相应算法如下:
c/**
* Double List structure
*/
struct rt_list_node
{
struct rt_list_node *next; /**< point to next node. */
struct rt_list_node *prev; /**< point to prev node. */
};
typedef struct rt_list_node rt_list_t; /**< Type for lists. */
cstruct rt_thread
{
char name[RT_NAME_MAX]; /**< the name of thread */
rt_list_t list; /**< the object list */
rt_list_t tlist; /**< the thread list */
rt_uint8_t current_priority; /**< current priority */
rt_uint8_t init_priority; /**< initialized priority */
};
typedef struct rt_thread *rt_thread_t;
#define rt_container_of(ptr, type, member) \
((type *)((char *)(ptr) - (unsigned long)(&((type *)0)->member)))
//ptr: 成员首地址(指针域地址,例如 rt_thread_priority_table[highest_ready_priority].next)
//type: 结构体类型(例如 struct rt_thread)
//member: 结构体成员名称(例如 tlist)
RT-Thread 抢占式调度实现
两个线程,低优先级t2任务while(1)执行耗时任务,高优先级t1任务抢占式打印随后阻塞
调度器执行顺序:
1.高优先级任务先执行,执行到rt_thread_mdelay()调用rt_thread_sleep()中的rt_schedule()挂起
2.调度器介入,寻找到当前最高优先级任务(t2)运行
3.低优先级任务时间片未到情况下,由于高优先级任务rt_thread_mdelay()超时,其定时计数器变化
4.下一个节拍周期到达,定时执行rt_tick_increase(),调用rt_timer_check()中的timeout_func()
5.由函数指针跳转到rt_thread_timeout(),执行其中的rt_schedule()
6.进入PendSV中断处理函数进行线程上下文切换
FreeRTOS内存管理
FreeRTOS的内存位于.bss段,并非heap(启动文件中的堆空间大小)
使用pvPortMalloc函数申请内存时,也是从这个系统堆(实际为bss段)中申请的
c#define configTOTAL_HEAP_SIZE ( ( size_t ) ( 100 * 1024 ) // 申请100KB内存用于RTOS系统堆内存
在map文件中可以看到FreeRTOS使用一个静态数组作为HEAP,以我使用的heap_4.c内存管理策略来说,它定义在heap_4.c这个文件里面。因为这个HEAP来自于静态数组,所以它存在于数据段(具体为.bss段),并不是我一开始认为的FreeRTOS所使用的HEAP来自于系统的堆。
c.bss zero 0x2021'7d1c 0x1'9000 heap_4.o [35] // 实际位于.bss段
Entry Address Size Type Object
----- ------- ---- ---- ------
ucHeap 0x2021'7d1c 0x1'9000 Data Lc heap_4.o [35] // 起始地址与大小
FreeRTOS任务调度
- 系统时钟判断最高优先级任务进行调度
- 当前任务主动执行taskYIELD()或portYIELD_FROM_ISR()让出CPU使用权
FreeRTOS创建任务
在堆中通过pvPortMalloc分配内存给TCB
任务堆栈
在创建任务时,可以选择动态创建或静态创建,静态的任务栈在任务结束后无法被回收,动态的可以
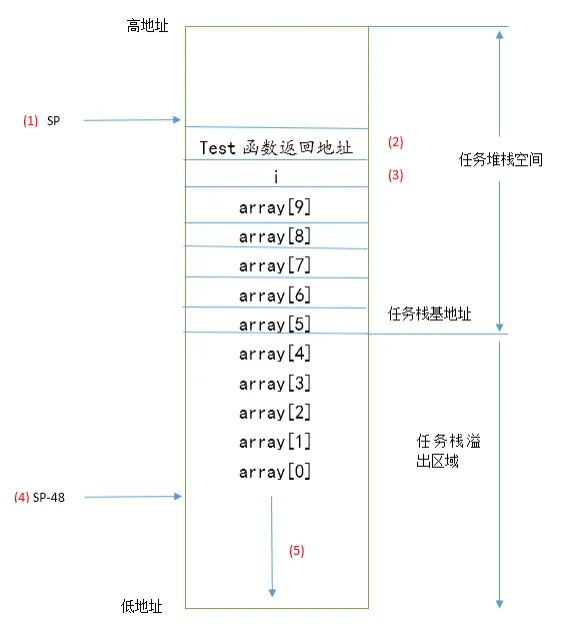
RTOS堆栈溢出的检测
方案1:在调度时检查栈指针是否越界(任务保存有栈顶和栈大小信息,每次切换时检查栈指针是否越界)
- 优点:检测较快
- 缺点:对于任务运行时溢出,而切换前又恢复正常的情况无法检测
方案2:在调度时检查栈末尾的16个字节是否发生改变(创建任务时初始化为特定字符,每次切换时判断是否被改写)
- 优点:可检出几乎所有溢出
- 缺点:检测较慢
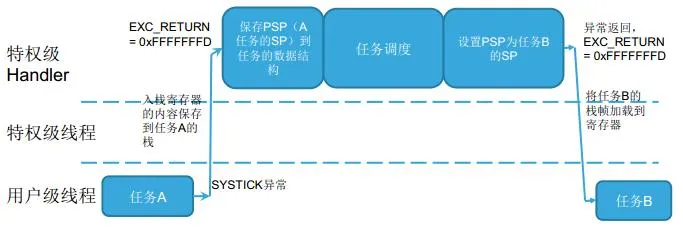
RT-Thread PendSV系统调用--上下文切换
省流版:OS调度依赖于systick,最低优先级,ISR抢占OS调度先执行,OS调度在无ISR时实际由PendSV执行,若在调度时ISR到来那么插队执行ISR,再调度
一、方法1-无PendSV-SysTick最高优先级(Fault异常):
- 假如在产生异常时,CPU正在响应另一个中断ISR,而SysTick的优先级又大于ISR,在这种情况下,SysTick就会抢占ISR,获取CPU使用权,但是在SysTick中不能进行上下文切换,因为这将导致中断ISR被延迟,这在实时要求的系统中是不能容忍的,并且由于IRQ未得到响应,执行了线程,触发Fault异常。
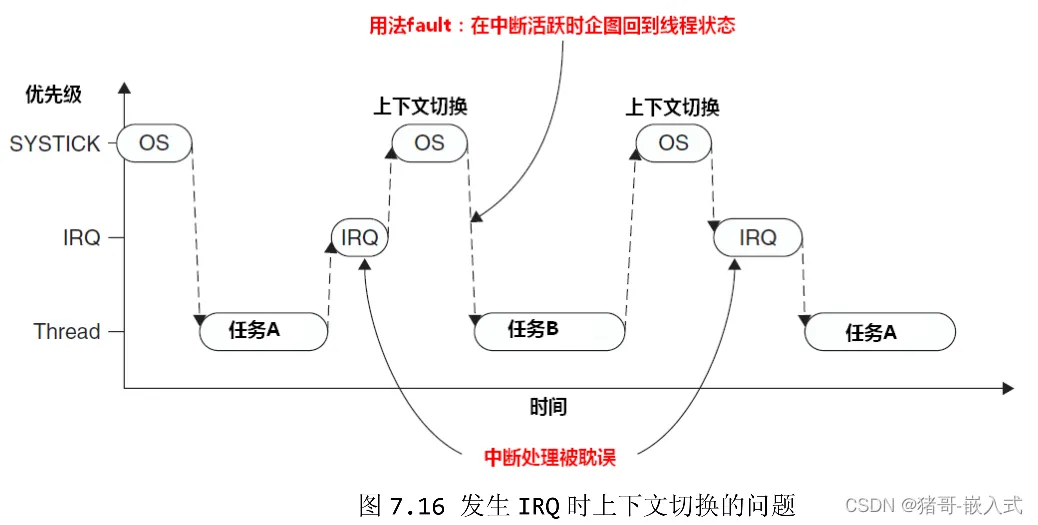 二、方法2-无PendSV-SysTick最低优先级(无法满足实时):
二、方法2-无PendSV-SysTick最低优先级(无法满足实时):
- 将SysTick的优先级设置为最低,然后在SysTick中进行上下文切换
- 一般OS在调度任务时,会关闭中断,也就是进入临界区,而OS任务调度是要耗时的,这就会出现一种情况: 在任务调度期间,如果新的外部IRQ发生,CPU将不能够快速响应处理。

三、PendSV-SysTick最低优先级(实际方案)
- 将SysTick的优先级调低,避免了触发Fault的问题,但是会影响外部中断IRQ的处理速度,那有没有进一步优化的方法呢?答案就是PenSV。因为PendSV有【缓期执行】的特点,所以可以将上图中的OS拆分,分成2段:
- 滴答定时器中断,制作业务调度前的判断工作,不做任务切换。
- 触发PendSV,PendSV并不会立即执行,因为PendSV的优先级最低,如果此时正好有IRQ请求,那么先响应IRQ,最后等到所有优先级高于PendSV的IRQ都执行完毕,再执行PendSV,进行任务调度。(PendSV可被打断)
实际方案的缺陷:(系统节拍被ISR打乱)
- SysTick的优先级最低,那如果外部IRQ比较频繁,是不是会导致SysTick经常被挂起,然后滞后,导致Systick的节拍延长,进而导致不准啊?
- 因为1的原因,导致任务的执行调度就不够快了?
四、若将SysTick设置最高优先级,保证系统节拍(实时性不足,无法响应ISR)
- 这样似乎解决了问题,但是又带来了一个问题,SysTick的优先级最高,而且又是周期性的触发,会导致经常抢占外部IRQ,这就会导致外部IRQ响应变慢,
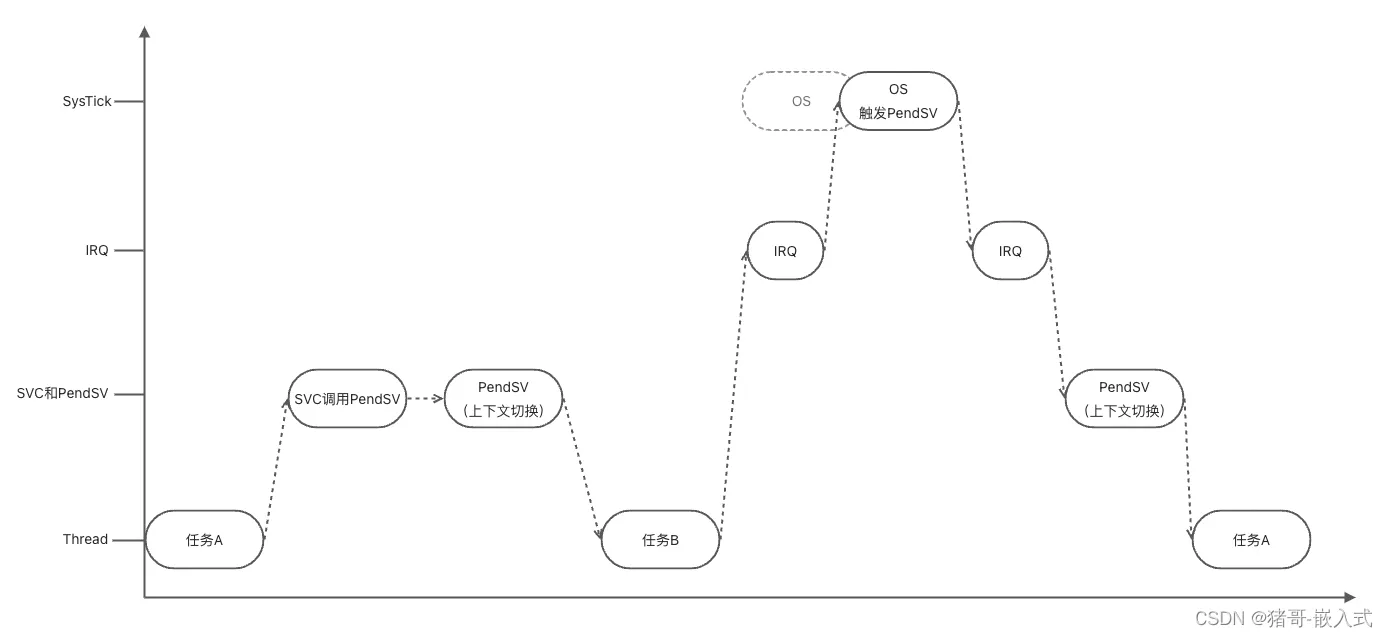
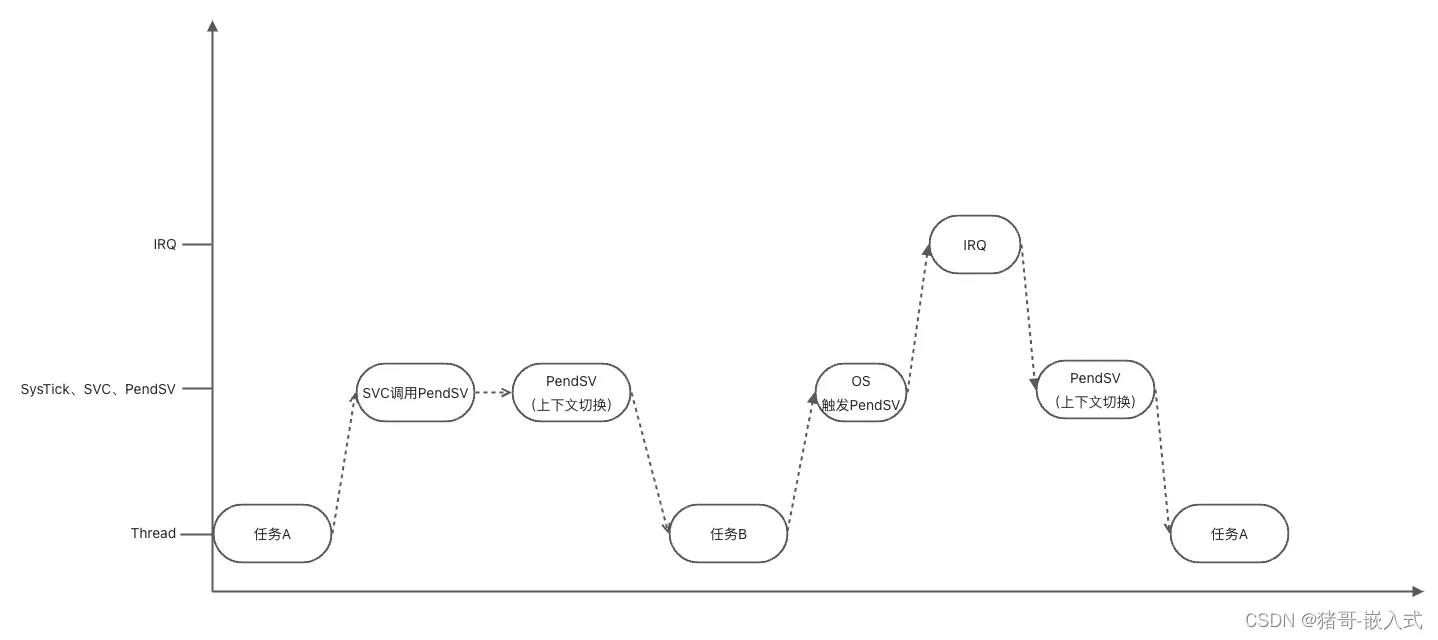
实际方案:
- 滴答定时器中断,制作业务调度前的判断工作,不做任务切换。
- 触发PendSV,PendSV并不会立即执行(优先级最低),如果此时正好有IRQ请求,那么先响应IRQ,最后等到所有优先级高于PendSV的IRQ都执行完毕,再执行PendSV,进行任务调度。
具体实现流程:
1.任务A请求SVC(supervisor call,系统调用)进行任务切换
2.内核收到请求,挂起PendSV异常
3.CPU退出SVC后进入PendSV,执行上下文切换
4.PendSV执行完毕后返回任务B
5.中断发生,执行ISR(子中断服务程序)
6.ISR执行中,心跳到达,SysTick异常发生,抢占了ISR
7.PendSV准备进行上下文切换
8.SysTick退出后,继续执行ISR
9.ISR执行完毕,进入PendSV进行上下文切换
10.切换至任务A

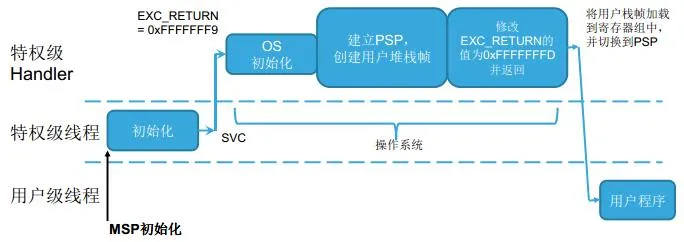
SVC中断
SVC(系统服务调用)和 PendSV( 可悬挂系统调用 )。
它们多用于在操作系统之上的软件开发中。 SVC 用于产生系统函数的调用请求。 例如,操作系统不让用户程序直接访问硬件,而是通过提供一些系统服务函数,用户程序使用 SVC 发出对系统服务函数的呼叫请求,以这种方法调用它们来间接访问硬件。因此,当用户程序想要控制特定的硬件时,它就会产生一个 SVC 异常,然后操作系统提供的 SVC 异常服务例程得到执行,它再调用相关的操作系统函数,后者完成用户程序请求的服务。
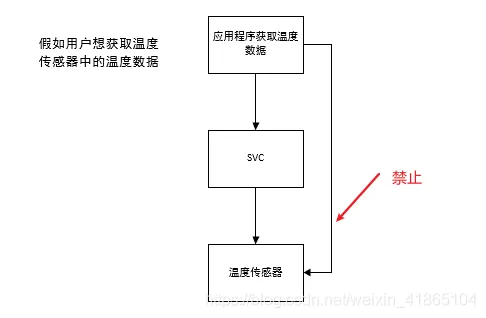 系统调用处理异常,用户与内核进行交互,用户想做一些内核相关功能的时候必须通过SVC异常,让内核处于异常模式,才能调用执行内核的源码。触发SVC异常,会立即执行SVC异常代码。
系统调用处理异常,用户与内核进行交互,用户想做一些内核相关功能的时候必须通过SVC异常,让内核处于异常模式,才能调用执行内核的源码。触发SVC异常,会立即执行SVC异常代码。
为什么要用SVC启动第一个任务?因为使用了OS,任务都交给内核。总不能像裸机调用普通函数一样启动一个任务。
FreeRTOS中任务调度器触发了 SVC 中断来启动第一个任务,之后的工作都靠 PendSV 和 SysTick 中断触发来实现
SVC是系统服务调用,由 SVC 指令触发调用。在 FreeRTOS 中用来在任务调度中开启第一个任务。触发指令:svc 0
SVC中断就是软中断,给用户提供一个访问硬件的接口PendSV中断相对SVC来说,是可以被延迟执行的,用于任务切换
FreeRTOS中_FROM_ISR
作用:在中断中调用的API,其禁用了调度器,无延时等阻塞操作,保证临界区资源快进快出访问
RT-Thread中没有类似的API,仅有延时参数选项
RT-Thread 同步互斥与通信
| 内核对象 | 生产者 | 消费者 | 数据/状态 | 说明 |
|---|---|---|---|---|
| Semaphore | all | all | 数量0~n | 维护的资源个数 |
| Mutex | A上锁 | 只能A开锁 | bit 0、1 | 单一互斥资源 |
| Event | all | all | 多个bit | 传递事件用以唤醒,实现多任务的同步 |
| Mail box | all | all | 固定4 Byte | 传递指针 |
| Message queue | all | all | 若干数据 | 传递数据(结构体) |
| Signal | 软中断,用以唤醒 |
RT-Thread 消息队列、邮箱、信号量区别
全局变量通信:可以承载通信的内容,但无法告接收方知数据的到达(需要接收方轮询,占用资源)
信号量:告知接收方信息到达,但是未告知数据内容
消息队列:承载了信息内容,同时告知接收方信息到达
邮箱:4 Byte的通信,通过指针而非memcpy(),开销小
RTOS优先级的分配原则
依据任务对响应的敏感性、执行时长(RTOS抢占式,会导致饥饿)
串口接收中断等任务优先级最高
电机PID计算以及控制需要固定控制周期,优先级较高
看门狗,按键处理中等、
最低的APP层的心跳和信息显示任务
FreeRTOS优先级
高优先级数字大
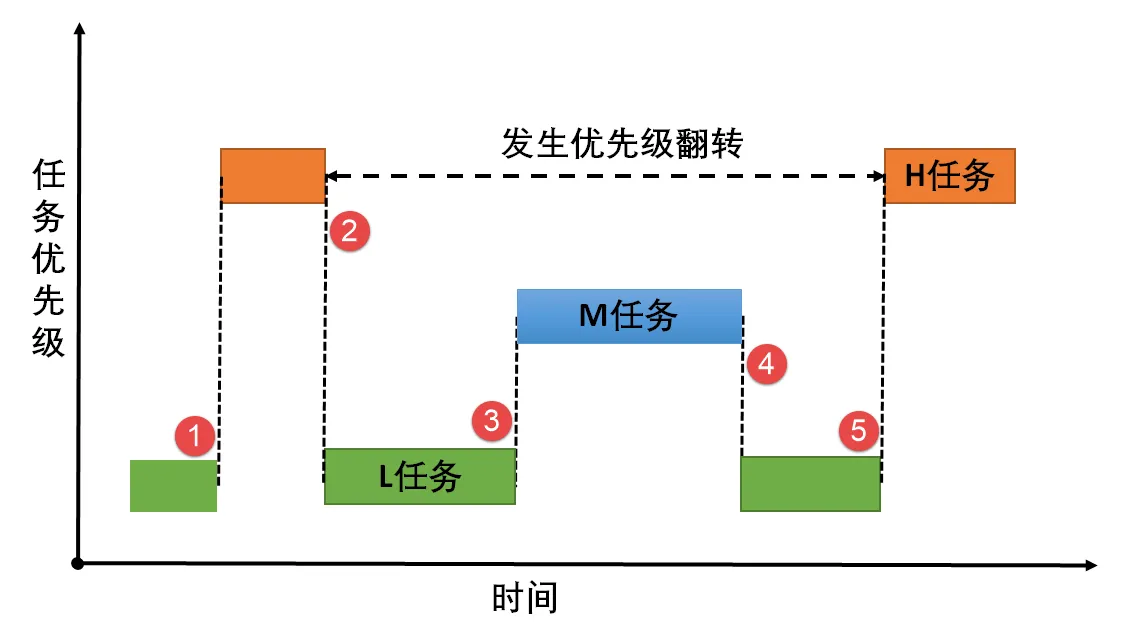
优先级反转
使用信号量时
高优先级任务被低优先级任务阻塞,导致高优先级任务迟迟得不到调度。但其他中等优先级的任务却能抢到CPU资源。-- 从现象上来看,好像是中优先级的任务比高优先级任务具有更高的优先权。
RT-Thread内核移植
CPU架构移植:
在不同的架构,如RISC-V、Cortex-M上运行,上下文切换,时钟配置以及中断操作等的适配
BSP移植:
对于同架构CPU,对不同外设进行适配、动态内存管理
RT-Thread POSIX标准
Portable operating system interface,保证应用程序在不同OS下的可移植性
RT-Thread单元测试
定义:对软件中的最小可测试单元进行检查和验证(函数、方法、类、功能模块)
utest框架(unit test)
RT-Thread 崩溃调试
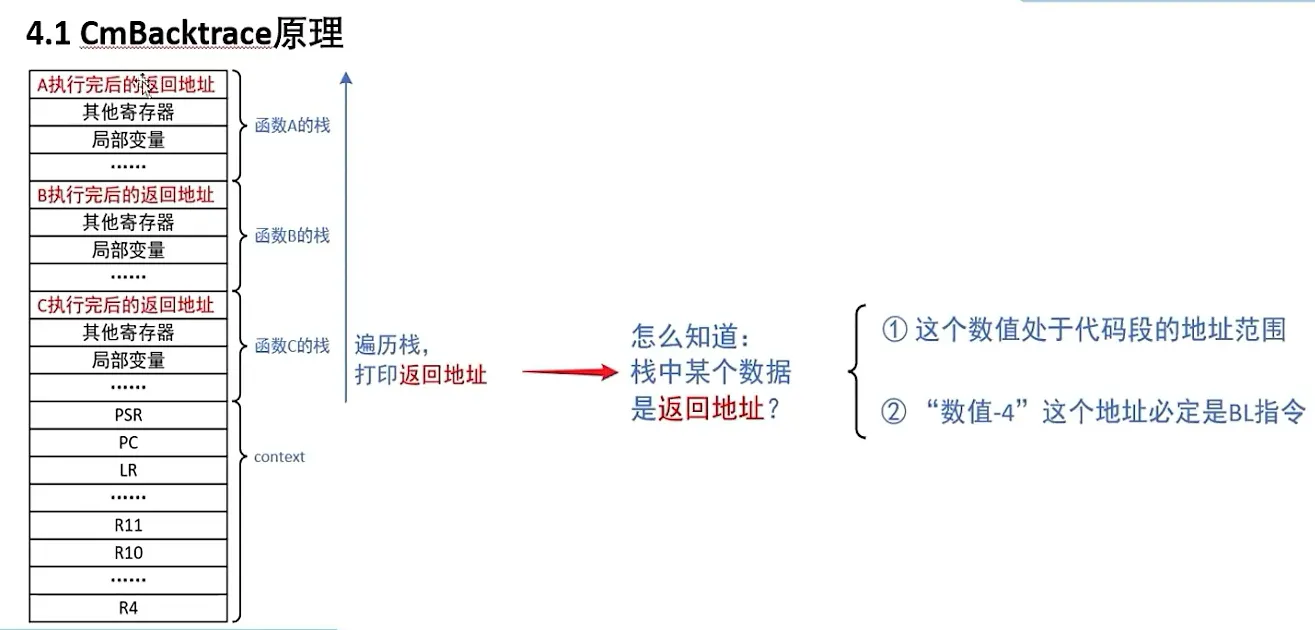
CmBacktrace 函数,崩溃后保存线程栈和寄存器值,可逆向分析调用关系
RTOS中多线程看门狗
方案1:在最低优先级线程喂狗,若高优先级线程长时间抢占,则看门狗超时
方案2:监控各线程调度情况,每个线程放置定时任务喂狗,超时则单个线程阻塞
计算机体系结构与硬件
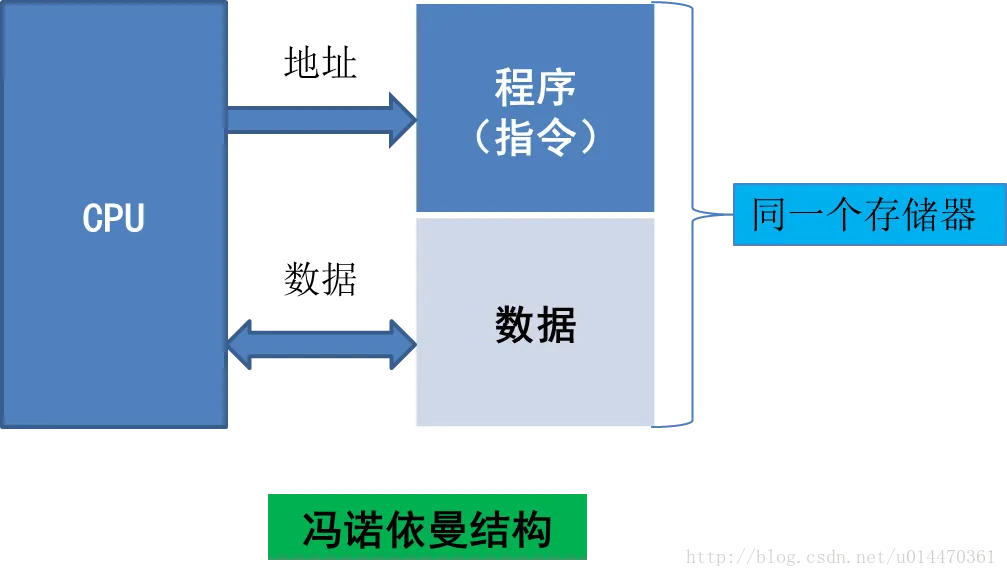
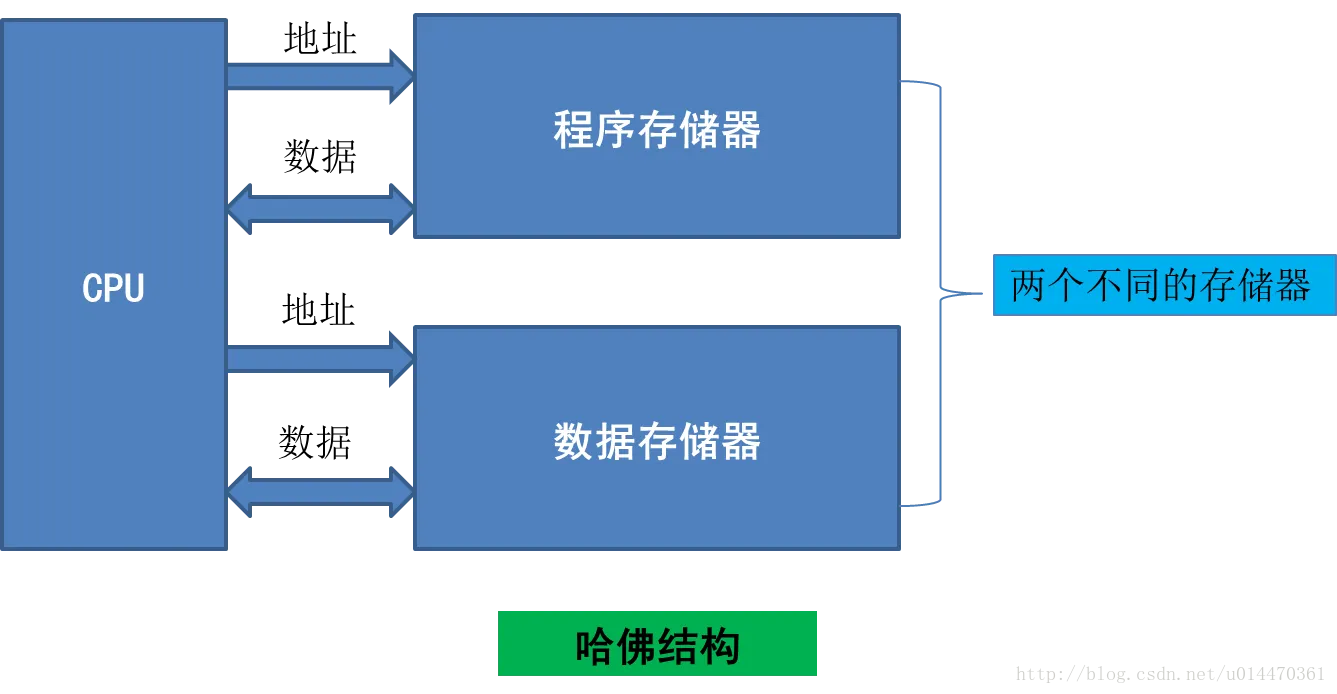
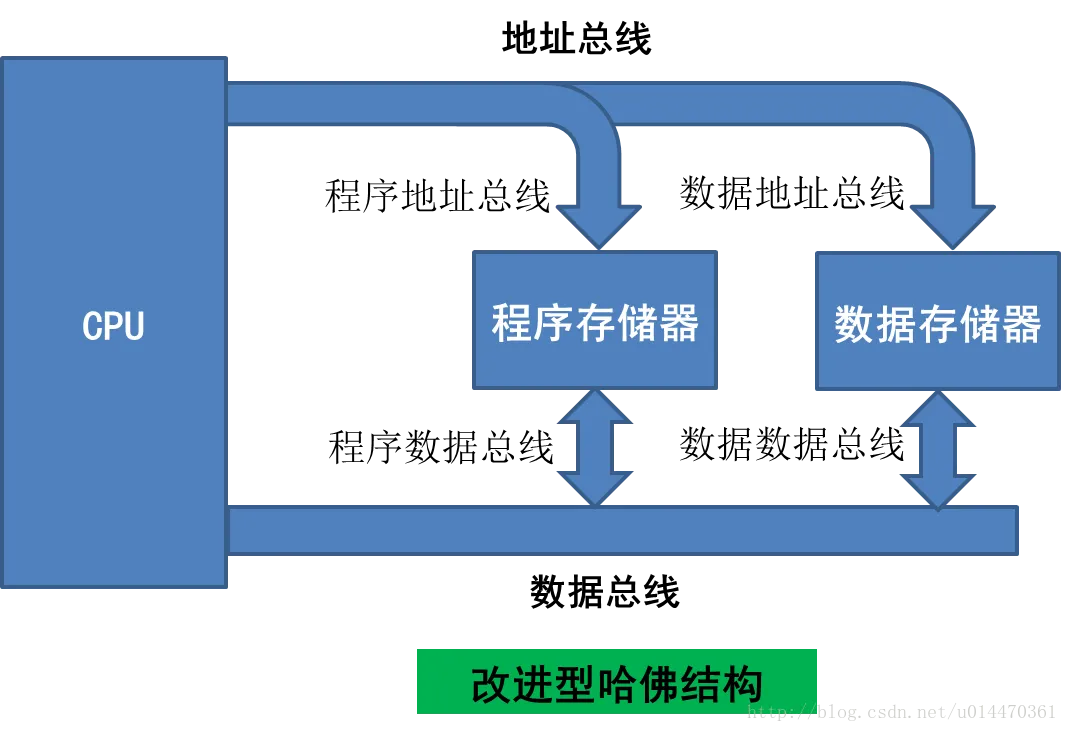
冯诺依曼与哈弗体系结构
冯‘诺依曼体系:计算机硬件由运算器、控制器、存储器、输入设备和输出设备五大部分组成
| 体系 | 冯诺依曼 | 哈佛 | 改进的哈佛(现代ARM) |
|---|---|---|---|
| 数据与程序存储方式 | 存储在一起 | 分开存储 | 分开存储 |
| CPU总线条数 | 1*(地址+数据) | 2*(地址+数据) | 1*(地址+数据)(新增cache,cpu由1条总线读cache,cache有2条总线) |
| 取指操作与取数据操作 | 串行 | 并行,可预取指 | 并行,可预取指 |
| 缺点 | 成本低 | 成本高 | 综合 |
| 优点 | 执行效率低 | 效率高,流水线(取指、译码、执行) | 同哈佛 |
ARM架构与x86架构区别
最主要区别:指令集
- ARM:精简指令集RISC
- X86:复杂指令集CISC
功耗
- ARM:主要面向低功耗
- X86:通过制程弥补功耗劣势
性能
ARM:低性能,顺序执行能力强,流水线指令集,主频低于1G
X86:高性能,乱序执行能力强,主频高
流水线
CPU的流水线(Pipeline)是一种提高处理器执行效率的技术,将指令执行过程划分为多个阶段,并使多个指令在不同阶段之间并行执行,从而实现指令级并行。
CPU流水线通常包括以下几个阶段:
- 取指(Instruction Fetch):从内存中获取下一条指令。
- 译码(Instruction Decode):将指令解析成对应的操作码和操作数,并为执行阶段做准备。
- 执行(Execute):执行指令的具体操作,如算术运算、逻辑运算等。
- 访存(Memory Access):如果指令需要访问内存,这个阶段用于进行数据的读取或写入操作。
- 写回(Write Back):将执行结果写回到寄存器中,更新寄存器的内容。
每条指令在流水线中按顺序通过不同的阶段,形成一个连续的流水线操作。当一个指令完成当前阶段的操作后,就会进入下一阶段,同时下一条指令进入到当前阶段,从而实现指令的并行执行。
通过流水线技术,CPU可以实现更高的处理能力和更好的性能指标,因为在同一时钟周期内可以同时执行多个指令。然而,流水线也会引入一些问题,如流水线的阻塞、冲突和分支预测问题,可能导致流水线效率下降。为了解决这些问题,还可以采取一些技术手段,如超标量流水线、动态调度、乱序执行等。
一个任务执行阶段,开始下一个任务的取指、译码阶段
- 提高了吞吐量,但单任务的执行时间没有减少
- 受制于最慢的流水线
- 对程序员不可见
RISC5级流水线步骤
- 取指(访问Icache得到PC)
- 译码(翻译指令并从寄存器取数)
- 执行(运算)
- 访存(访问存储器,读取操作数)(4级流水线独有)
- 写回(将结果写回寄存器)(5级流水线独有)
ARM3级流水线步骤
- 取指
- 译码
- 执行
CPU、MCU、SOC区别
- CPU:运算器、控制器、寄存器组成,主要负责取指、放入寄存器、译码、执行指令并更新寄存器(仅存在理论之中)
- MPU:增强版的CPU
- MCU:CPU+RAM+ROM+I/O,在CPU的基础上加入片上RAM、Flash、串口、ADC等外设,在一块芯片上集成整个计算机系统
- SOC:MPU+RAM+ROM+I/O+特定功能模块(如电能计量、编解码),将MPU的计算能力和MCU的外设结合
Cache
高速 中等速度 低速
CPU <------> Cache <-----> RAM
Cache,就是一种缓存机制,它位于CPU和DDR RAM之间,为CPU和DDR之间的读写提供一段内存缓冲区。cache一般是SRAM,它采用了和制作CPU相同的半导体工艺,它的价格比DDR要高,但读写速度要比DDR快不少。例如CPU要执行DDR里的指令,可以一次性的读一块区域的指令到cache里,下次就可以直接从cache里获取指令,而不用反复的去访问速度较慢的DDR。又例如,CPU要写一块数据到DDR里,它可以将数据快速地写到cache里,然后手动执行一条刷新cache的指令就可以将这片数据都更新到DDR里,或者干脆就不刷新,待cache到合适的时候,自己再将内容flush到DDR里。总之一句话,cache的存在意义就是拉近CPU和DDR直接的性能差异,提高整个系统性能。
Cache分为I-Cache(指令缓存)与D-Cache(数据缓存)
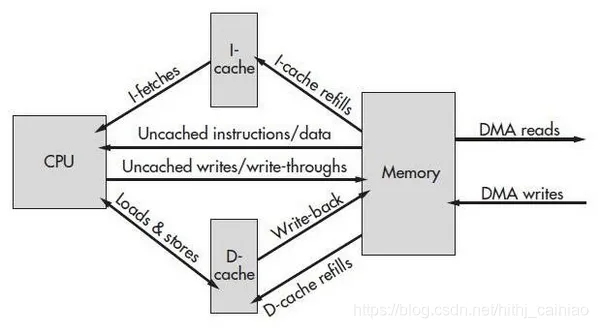
cache是多级的,在一个系统中你可能会看到L1、L2、L3, 当然越靠近core就越小,也是越昂贵。
CPU接收到指令后,它会最先向CPU中的一级缓存(L1 Cache)去寻找相关的数据,然一级缓存是与CPU同频运行的,但是由于容量较小,所以不可能每次都命中。这时CPU会继续向下一级的二级缓存(L2 Cache)寻找,同样的道理,当所需要的数据在二级缓存中也没有的话,会继续转向L3 Cache、内存(主存)和硬盘.
不能使用cache的情况
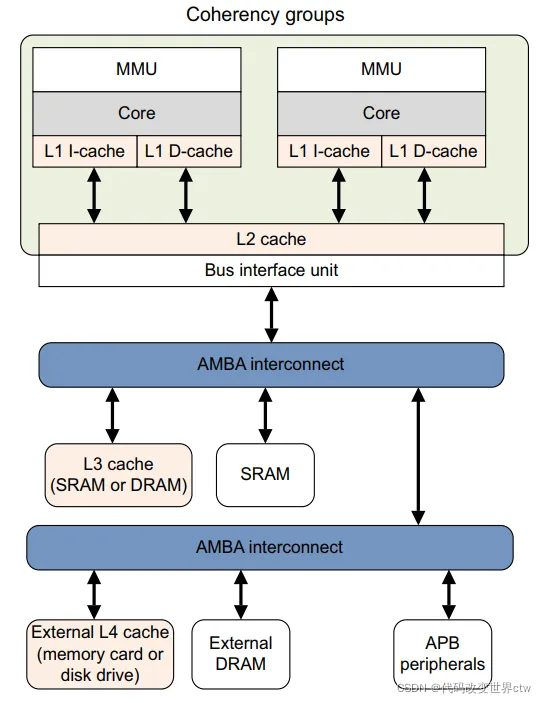
- CPU读取外设的内存数据,如果外设的数据本身会变,如网卡接收到外部数据,那么CPU如果连续2次读外设的操作相差时间很短,而且访问的是同样的地址,上次的内存数据还存在于cache当中,那么CPU第二次读取的可能还是第一次缓存在cache里数据。
- CPU往外设写数据,如向串口控制器的内存空间写数据,如果CPU第1次写的数据还存在于cache当中,第2次又往同样的地址写数据,CPU可能就只更新了一下cache,由cache输出到串口的只有第2次的内容,第1次写的数据就丢失了。
- 在嵌入式开发环境中,经常需要在PC端使用调试工具来通过直接查看内存的方式以确定某些事件的发生,如果定义一个全局变量来记录中断计数或者task循环次数等,这个变量如果定义为cache的,你会发现有时候系统明明是正常运行的,但是这个全局变量很长时间都不动一下。其实它的累加效果在cache里,因为没有人引用该变量,而长时间不会flush到DDR里
- 考虑双cpu的运行环境(不是双核)。cpu1和cpu2共享一块ddr,它们都能访问,这块共享内存用于处理器之间的通信。cpu1在写完数据到后立刻给cpu2一个中断信号,通知cpu2去读这块内存,如果用cache的方法,cpu1可能把更新的内容只写到cache里,还没有被换出到ddr里,cpu2就已经跑去读,那么读到的并不是期望的数据。
为何启动时关闭Cache
在嵌入式系统和某些应用程序中,启动时关闭指令缓存(Instruction Cache)和数据缓存(Data Cache)是一种常见的做法。以下是一些原因:
- 避免缓存冲突:在启动阶段,代码和数据通常是从外部存储器(如闪存)加载到内部存储器(如RAM)中。由于这些加载过程往往涉及重复的读写操作,启动时关闭缓存可以防止缓存中的“旧”数据对加载过程产生冲突,确保正确加载并执行新的代码和数据。
- 简化启动过程:在关闭缓存的情况下,处理器将直接从内存中读取指令和数据,而不依赖于缓存。这样可以避免额外的缓存管理开销,并简化启动代码的编写和调试过程。
- 确保数据的一致性:某些应用程序要求数据在内存和外部设备之间保持一致。在关闭缓存的情况下,每次访问数据都将直接从内存取,确内存中的数据始终与外部设备保持一致,关闭存并不适用于所有应用场景,并且可能会对性能产生负面影响。在实际应用中,应根据具体的系统需求和性能要求来决定是否关闭缓存。
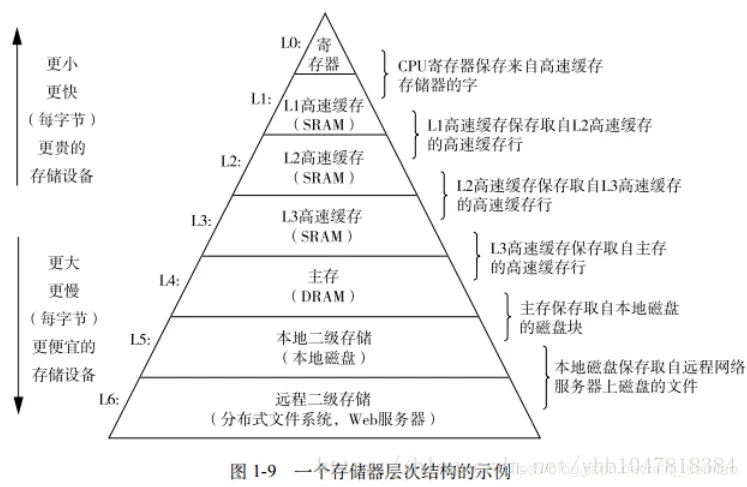
存储器层次结构与分类
Cortex-M
寄存器
Cortex-M 系列 CPU 的寄存器组里有 R0~R15 共 16 个通用寄存器组和若干特殊功能寄存器
SP指向:栈顶
LR指向:函数调用结束后的返回地址
PC指向:下一条指令
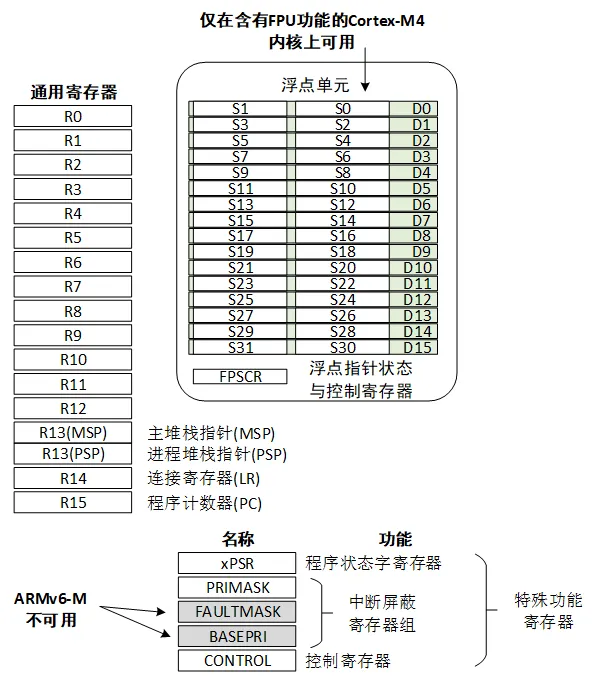
寄存器R13在ARM指令中常用作堆栈指针SP,寄存器R14称为子程序链接寄存器LR(LinkRegister),寄存器R15用作程序计数器(PC)。 ARM微处理器共有37个32位寄存器,其中31个为通用寄存器,6个位状态寄存器。通用寄存器R0~R14、程序计数器PC(即R15)是需要熟悉其功能的。
R13 SP MSP PSP
MSP的含义是Main_Stack_Pointer,即主栈 PSP的含义是 Process_Stack_Pointer,即任务栈
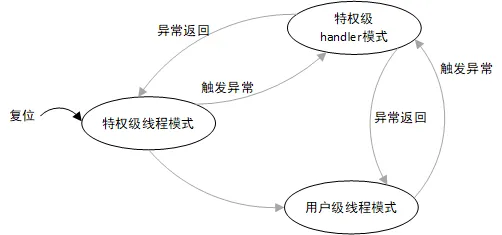
- Cortex-M3内核中有两个堆栈指针(MSP & PSP),但任何时刻只能使用到其中一个。
- 复位后处于线程模式特权级,默认使用MSP。
- 通过SP访问到的是正在使用的那个指针,可以通过MSR/MRS指令访问指定的堆栈指针。
- 通过设置CONTROL寄存器的bit[1]选择使用哪个堆栈指针。CONTROL[1]=0选择主堆栈指针;CONTROL[1]=1选择进程堆栈指针。
- Handler模式下,只允许使用主堆栈指针MSP。
典型的OS环境中,MSP和PSP的用法如下:
- MSP用于OS内核和异常处理。
- PSP用于应用任务。
- CONTROL的bit1为0,SP = MSP CONTROL的bit1为1,SP = PSP
在裸机开发中,CONTROL的bit1始终是0,也就是说裸机开发中全程使用程MSP,并没有使用PSP。在执行后台程序(大循环程序)SP使用的是MSP,在执行前台程序(中断服务程序)SP使用的是MSP。 在OS开发中,当运行中断服务程序的时候CONTROL的bit1是0,SP使用的是MSP;当运行线程程序的时候CONTROL的bit1是1,SP使用的是PSP。

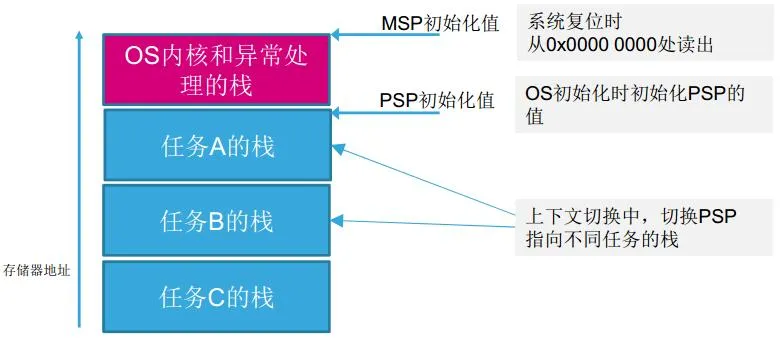
初始化时的操作
- 系统复位时从0x00000000处读出MSP的初始值。
- 在OS初始化时,对PSP进行初始化。
任务调度时的操作
- 用任务A的SP执行入栈操作,并保存任务A的SP。
- 设置PSP指向任务B的栈空间,用任务B的SP执行出栈,随后开始执行任务B。
用户级和特权级
Cortex-M分为两个运行级别
处理模式:异常与中断,工作在特权级
线程模式:其他情况,可以工作在用户级和特权级
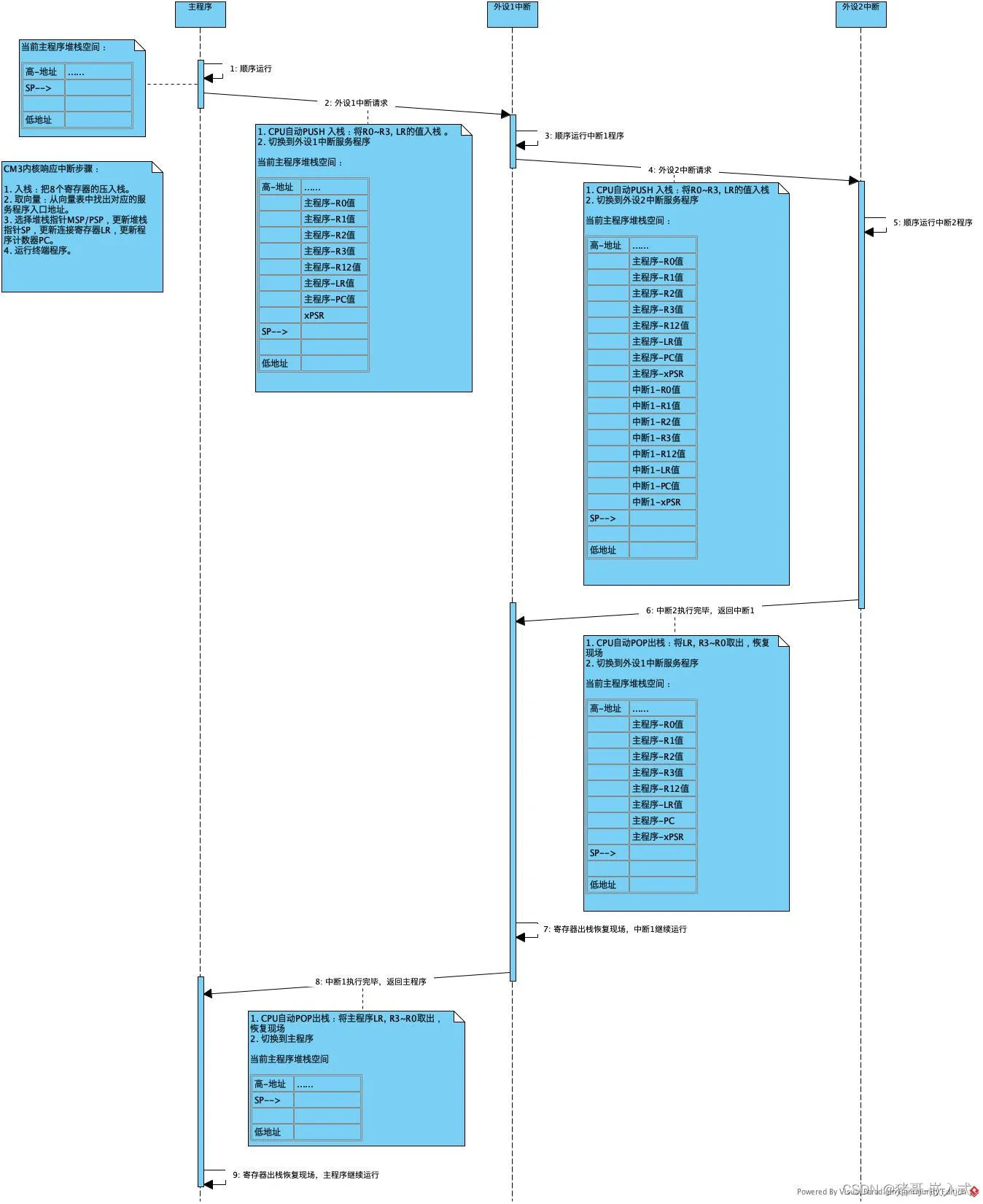
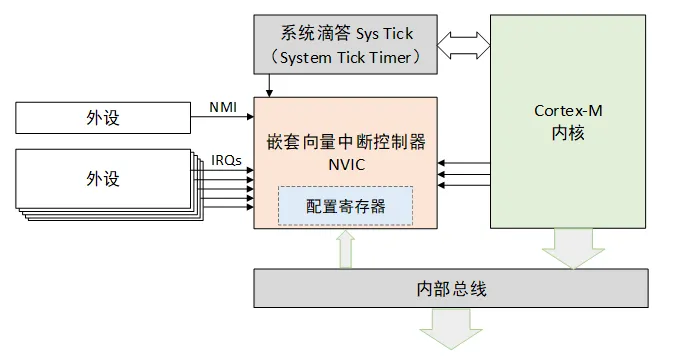
NVIC(嵌套向量中断控制器)
NVIC支持中断嵌套功能。当一个中断触发并且系统进行响应时,处理器硬件会将当前运行位置的上下文寄存器自动压入中断栈中,这部分的寄存器包括 PSR、PC、LR、R12、R3-R0 寄存器
M3 M4对比
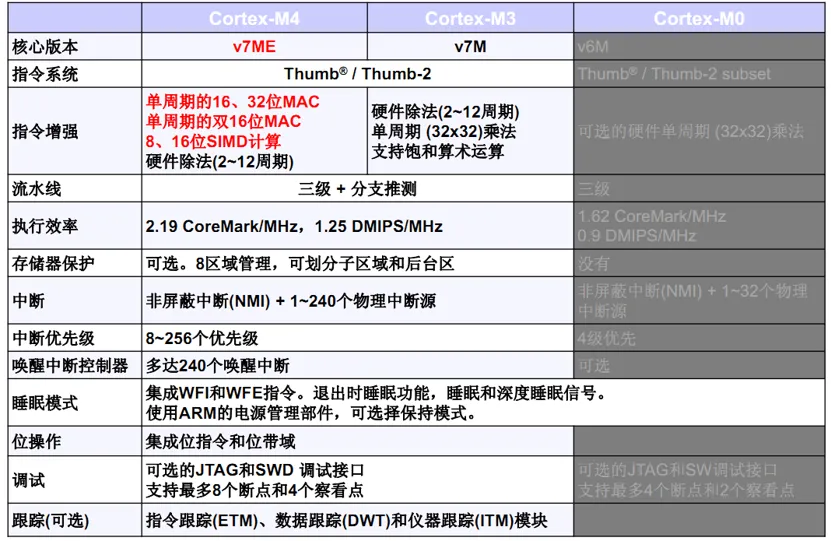
M4新增FPU浮点
相较于M3用软件方式计算浮点,硬件浮点计算更快
基础、语法
static关键字
【在函数体内】,【修饰局部变量】,其访问权限在函数内,仅初始化一次,存储于静态存储区(可通过其地址,在其他文件中访问修改,BUG!!!)
【在模块内,函数体外】,【修饰全局变量】将模块的全局变量限制在模块内部(仅供.c使用),不能跨文件共享
【在模块内】,【修饰函数】,该函数仅可被本模块调用,不能作为接口暴露给其他模块
注意:static 与 extern不可同时修饰一个变量
const关键字
变量一旦被初始化后无法修改。
常量指针与指针常量,* (指针)和 const(常量) 谁在前先读谁 ;*象征着地址,const象征着内容;谁在前面谁就不允许改变。
cint * const p; //a是一个指向整型数的常指针(指针指向不可以修改,整型数(指针指向的值)可以修改)(指针常量)
<==>const p
// const 修饰指针p
*p=10; // 指针指向的值可以修改
// p=&b; // 指针指向被限定
const int *p; //a是一个指向常整型数的指针(指针指向可以修改,整型数(指针指向的值)不可修改)(常量指针)
<==>const *p
// const 修饰*p
// *p=10; // 指针指向的值被限定
p=&b; // 指针指向可以修改
const int * const a; //a是一个指向常整形数的常指针(都不可修改)
void printArray(const int *arr, int size) //防止修改入参
const char* getString() //防止修改返回值,返回值为指针的时候
volatile关键字
作用:每次从内存或对应外设寄存器中取值放入CPU寄存器通用寄存器后进行操作,防止编译器优化
详解:CPU读取数据时,会从指定地址处取值并搬运到CPU通用寄存器中处理,在不加volatile时,对于频繁的操作,编译器会将代码的汇编指令进行优化,例子如下:
c // 比如要往某一地址送两指令:
int *ip = 0x12345678; //设备地址
*ip = 1; //第一个指令
*ip = 2; //第二个指令
// 编译器可能优化为:
int *ip = 0x12345678; //设备地址
*ip = 2; //第二个指令
// 造成第一条指令被忽略
volatile int *ip = 0x12345678; //设备地址
*ip = 1; //第一个指令
*ip = 2; //第二个指令
场合:寄存器、临界区访问的变量、中断函数访问的全局或static变量
Note:与Cache的区别:
- volatile是对编译器的约束,可以控制每次从RAM读取到通用寄存器,但无法控制从RAM到通用寄存器的过程(从RAM到寄存器要经过cache)。若两次被volatile修饰的读取指令过快,即使RAM中的值改变了,但由于读取过快没有更新cache,那么实际上搬运到通用寄存器的值来自于cache,此类情况下需要禁用cache。
- 编译器优化是针对于LDR命令的,从内存中读取数据到寄存器时不允许优化这一过程,而None-cache保护的是对内存数据的访问(volatile无法控制LDR命令执行后是否刷新cache)
#define 与 const区别
| 名称 | 编译阶段 | 安全性 | 内存占用 | 调试 |
|---|---|---|---|---|
| #define | 编译的预处理阶段展开替换 | 低 | 占用代码段空间(.text) | 无法调试 |
| const | 编译、运行阶段 | 有数据类型检查 | 占用数据段空间(.data常量区) | 可调式 |
防止头文件重复引用
当程序中第一次 #include 该文件时,由于 _NAME_H 尚未定义,所以会定义 _NAME_H 并执行“头文件内容”部分的代码;当发生多次 #include 时,因为前面已经定义了 _NAME_H,所以不会再重复执行“头文件内容”部分的代码。
c#ifndef _NAME_H
#define _NAME_H
//头文件内容
#endif
函数调用与栈、寄存器
cvoid fun(int a, int b);
fun(1, 2); // 调用函数时,入栈顺序为参数从右往左,从而取参数时从左往右
| 1 |
| 2 |
——
右边的参数先入栈,存放在R0-R3中,多余4个的参数存放在任务栈中
返回值在R0寄存器
全局变量和局部变量区别
全局变量存储在静态存储区,局部变量存储在栈中
堆栈溢出原因
动态内存分配后未正确回收,内存泄漏
函数递归调用深度太深,栈深度不够
局部变量与全局变量重名
局部变量在栈中;全局变量在静态存储区
局部变量作用域在{}内,就近原则
访问内存中某地址数据
c// 读取
int result=*(int *)0x123456; // 方法1
int *ptr=const(int *)0x123456; // 方法2
int result=*ptr;
// 修改
*(int * const)(0x56a3) = 0x3344; // 方法1
int * const ptr = (int *)0x56a3; // 方法2
*ptr = 0x3344;
枚举类型
cenum DAY {
MON=1, TUE, WED, THU, FRI, SAT, SUN
};
int main() {
enum DAY day;
day = WED;
printf("%d",day); // 3
return 0;
}
enum COLOR {
black, // 默认为0
white, // 默认+1
red
};
enum COLOR {
black = 1, // 手动指定起始值
white,
red
};
enum COLOR {
black, // 0
white = 3,
red // 4
};
float精度
- float的精度是保证至少7位有效数字是准确的
- float的取值范围[-3.4028235E38, 3.4028235E38],精确范围是[-340282346638528859811704183484516925440, 340282346638528859811704183484516925440]
(1条消息) float的精度和取值范围_float精度_AlbertS的博客-CSDN博客
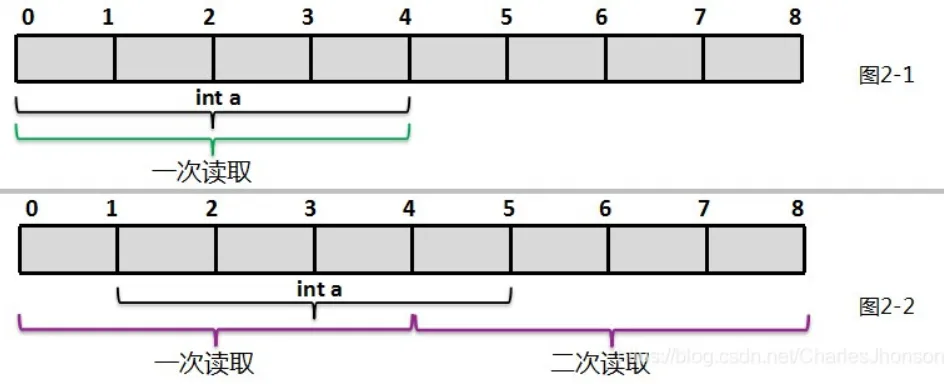
结构体字节对齐
字节对齐的作用就是规定数据在内存中的存储起始地址必须是某个特定字节数(通常是数据类型的大小)的整数倍。
1.读取效率问题
以32位机为例,它每次取32个位,也就是4个字节。以int型数据为例,如果它在内存中存放的位置按4字节对齐,也就是说1个int的数据全部落在计算机一次取数的区间内,那么只需要取一次就可以了。如图2-1。如果访问未对齐的内存,处理器需要作两次内存访问,很不巧,这个int数据刚好跨越了取数的边界,这样就需要取两次才能把这个int的数据全部取到,如图2-2,这样效率也就降低了
2.存储空间占用
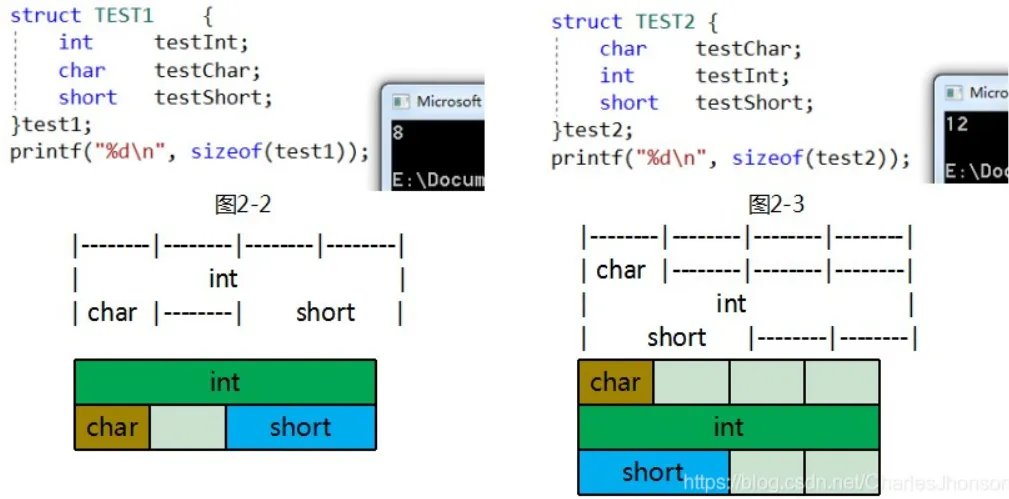
排列顺序不同时占用空间也不同
结构体嵌套时
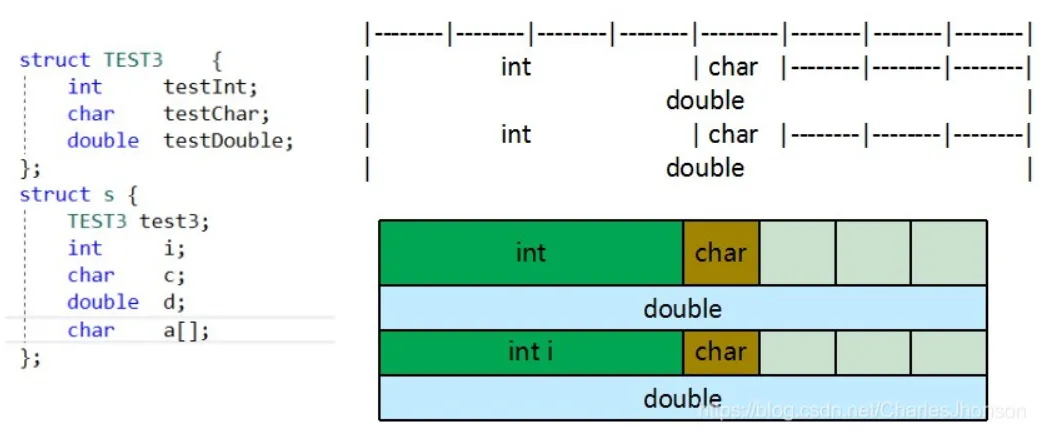
3. 实际使用
c++#pragma pack (n) // 编译器将按照n个字节对齐;
#pragma pack() // 恢复先前的pack设置,取消设置的字节对齐方式
#pragma pack (1) // 1字节对齐
typedef struct TestNoAlign {
unsigned char u8_test1; // 1
unsigned int u32_test2; // 4
double d8_test3; // 8
}TestNoAlign;
#pragma pack () // 取消
typedef struct TestAlign {
unsigned char u8_test1; // 1+3
unsigned int u32_test2; // 4
double d8_test3; // 8
}TestAlign;
int main(void)
{
printf("sizeof(TestNoAlign) is %d sizeof(TestAlign) is %d \n",
sizeof(TestNoAlign),sizeof(TestAlign));
return 0;
}
// 13 & 16
联合体
在同一地址空间中存储不同类型的数据
ctypedef union test_u{
int a;
char b;
}test;
test t;
t.a = 0x12345678;
if(t.b == 0x78) {
printf("小端\n"); // 低地址0x00000000 放低字节0x78
}
else {
printf("大端\n"); // 低地址0x00000000 放高字节0x12
}
实际使用:分离高低字节
cunion div
{
int n; // n中存放要进行分离高低字节的数据
char a[4]; // 一个整形占两个字节,char占一个字节,a[2]将n分为了两部分
}test;
test.n = 0x12345678; // 寄存器赋值
TH1 = test.a[0]; // test.a[0]中存储的是低位数据 0x78
TL1 = test.a[3]; // test.a[1]中储存了test.n的高位数据 0x12
实际使用:寄存器定义与位域
cunion test {
uint32_t reg;
struct {
uint32_t reserve:4; // 占用低字节的4bit
uint32_t ctrl:4;
uint32_t enable:5;
uint32_t dis:3;
uint32_t stat:1;
uint32_t loop:7;
uint32_t ext:2;
uint32_t mode:6; // 位域和为32
}bits;
};
int main(void) {
union test mytest;
mytest.reg = 0xa5a5a5a5;
printf("reg value=0x%x\n", mytest.reg);
printf("reserve(3:0)=0x%x\n", mytest.bits.reserve);
printf("ctrl(7:4)=0x%x\n", mytest.bits.ctrl);
printf("enable(12:8)=0x%x\n", mytest.bits.enable);
printf("dis(15:13)=0x%x\n", mytest.bits.dis);
printf("stat(16:16)=0x%x\n", mytest.bits.stat);
printf("loop(23:17)=0x%x\n", mytest.bits.loop);
printf("ext(25:24)=0x%x\n", mytest.bits.ext);
printf("mode(31:26)=0x%x\n", mytest.bits.mode);
return 0;
}
取u32的某一字节
c// 方法1
union bit32_data {
uint32_t data;
struct {
uint8_t byte0;
uint8_t byte1;
uint8_t byte2;
uint8_t byte3;
}byte;
};
union bit32_data num;
num.data = 0x12345678;
printf("byte0 = 0x%x\n", num.byte.byte0);
printf("byte1 = 0x%x\n", num.byte.byte1);
printf("byte2 = 0x%x\n", num.byte.byte2);
printf("byte3 = 0x%x\n", num.byte.byte3);
// 方法2
#define GET_LOW_BYTE0(x) ((x >> 0) & 0x000000ff) /* 获取第0个字节 */低
#define GET_LOW_BYTE1(x) ((x >> 8) & 0x000000ff) /* 获取第1个字节 */
#define GET_LOW_BYTE2(x) ((x >> 16) & 0x000000ff) /* 获取第2个字节 */
#define GET_LOW_BYTE3(x) ((x >> 24) & 0x000000ff) /* 获取第3个字节 */高
unsigned int a = 0x12345678;
printf("byte0 = 0x%x\n", GET_LOW_BYTE0(a));
printf("byte1 = 0x%x\n", GET_LOW_BYTE1(a));
printf("byte2 = 0x%x\n", GET_LOW_BYTE2(a));
printf("byte3 = 0x%x\n", GET_LOW_BYTE3(a));
strcmp
字符串1=字符串2,返回值=0; 字符串2〉字符串2,返回值〉0; 字符串1〈字符串2,返回值〈0。
位操作
c#define GetBit(x , bit) (((x) & (1 << (bit)) >> (bit)) // 获取将x的第y位(0或1)先左移再右移
#define SetBit(x , bit) ((x) |= (1 << (bit)) // 将X的第Y位置1
#define ClrBit(x , bit) ((x) &= ~(1 << (bit)) // 将X的第Y位清0
寄存器操作
ctypedef union Reg
{
u32 Byte;
struct
{
u32 a : 16; // bit [0-15]
u32 b : 8; // bit [16-23]
u32 c : 1; // bit 24
u32 d : 4; // bit[25-28]
u32 e : 1; // bit29
u32 f : 1; // bit30
u32 g : 1; // bit31
};
} Reg; // 占用u32大小空间
// usage
int main()
{
Reg misc;
misc.u32 = 0xffff0000;
misc.a = 0xaa;
printf("0x%x\n", misc.u32);
return 0;
}
// 执行结果:0xffff00aa
运算符优先级
如果一个表达式中的两个操作数具有相同的优先级,那么它们的结合律(associativity)决定它们的组合方式是从左到右或是从右到左。
*ptr++
cint num[] ={1,3,5,7,9};
int* ptr_num = num;
cout << *++ptr_num << endl;
//输出为 3
// 先对指针移位地址加1,然后解引用
cout << ++*ptr_num << endl;
// 输出为2
// 先解引用,再对数值+1
cout<< *ptr_num++ << " , "<< *ptr_num <<endl;
// 输出 1,3
// *与++优先级相同,右边线运算,但因为是后++,因此先解引用输出1,然后对指针++,指向第二个元素
cout << (*ptr_num)++ << " , "<< num[0] <<endl;
// 输出1,2
// 先解引用取指,修改值++
int a[5] = {0, 1, 2, 3, 4};
int *ptr = a;
printf("%d\n", *ptr);
printf("%d\n", *ptr++);
printf("%d\n", *ptr);
printf("%d\n", *++ptr);
printf("%d\n", *ptr);
// 0 0 1 2 2
常用情景
cunsigned char Get_CRC8_Check_Sum(unsigned char *pchMessage, unsigned int dwLength, unsigned char ucCRC8) {
unsigned char ucIndex;
while (dwLength --) {
ucIndex = ucCRC8^(*pchMessage++); // 先取指针的指向的值,使用完后指针自增
ucCRC8 = CRC8_TAB[ucIndex];
}
return(ucCRC8);
}
类型转换小Trick
将uint32_t数据赋值到uint8_t数组中:
cuint32_t data = 123;
uint8_t databuf[4] = {0};
*( (uint32_t *)databuf ) = data;//等价于memcpy(databuf, &data, 4);
比较浮点数
c++// float 4byte
abs(a-b) < 0.00001 1e^-5;
// double 8byte
// 判断阈值更小,16位左右
指针、数组指针、指针数组、函数指针
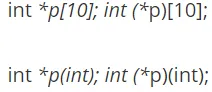
cint *p[10]; // 一个数组,存放有10个指针
int (*p)[10]; // 一个指针,指向长度为10的数组
int *p(int); // 一个函数,返回int*指针
int (*p)(int); // 一个函数指针,函数参数int,返回值int
int* (*a[10])(int) // 一个数组,存放10个函数指针
c// 第二种的用法举例
int a[][3]={{1,2,3},{4,5,6}};
int (*p)[3];
p=a;
// 这时,p指向元素1,p+1就指向元素4
// *(*(p+1)+2)就等价于a[1][2]这个元素值
函数指针与回调函数
c// 回调函数案例1
int callback_1(void) { //回调函数1主体
printf("call_1\n");
return 0;
};
int callback_2(void) { //回调函数2主体
printf("call_2\n");
return 0;
};
//定义一个处理函数,传入的是函数指针
int Handle(int (*callback)(void)) {
callback(); // 调用函数
}
int main()
{
//定义两个函数指针来指向函数地址
//不定义也可以,因为函数名称本身就是函数入口地址
int (*call1)(void) = &callback_1;
int (*call2)(void) = &callback_2;
Handle(call1); // 函数指针当参数调用
Handle(call2);
call1(); // 也可直接调用
//改变函数指针指向
call1=&callback_2;
Handle(call1);
return 0;
}
c++int max(int a, int b) {
return a > b ? a : b;
}
int min(int a, int b) {
return a < b ? a : b;
}
int (*f)(int, int); // 声明函数指针,指向返回值类型为int,有两个参数类型都是int的函数
int main(int argc, _TCHAR* argv[])
{
f = max; // 函数指针f指向求最大值的函数max
int c = (*f)(1, 2);
printf("The max value is %d \n", c);
f = min; // 函数指针f指向求最小值的函数min
c = (*f)(1, 2);
printf("The min value is %d \n", c);
return 0;
}
c// 结构体封装函数指针
struct DEMO
{
int x,y;
int (*func)(int,int); //函数指针
};
int add2(int x,int y)
{
return x+y;
}
void main()
{
struct DEMO demo;
demo.func = &add2; //结构体函数指针赋值
demo.func = add2; //这样写也可以
int ans = demo.func(3,4); // 调用
}
隐式类型转换
C 语言中不同类型的数据需要转换成同一类型,才可以计算
发生情况:
c// 赋值转换,可能造成精度降低,不安全
double pi = 3.14;
int num = pi;
转换规则:
-
转换按照数据长度增加的方向进行,以保证精度不降低。如 int 和 double相加时,int 会被隐式转换成 double 类型
-
如果两种类型的字节数一样,且一种有符号,另一种无符号,则转换成无符号类型(例如下)
-
char 类型和 short 类型参与运算时,必须先转换成 int 类型(整型提升)
c++unsigned int a = 6;
int b = -20;
int c;
((a+b) > 6) ? (c=1):(c=0);
//输出是0
存在unsigned且数据长度一致时,会将有符号类型隐私转换为无符号类型(负数存在问题)
二维数组
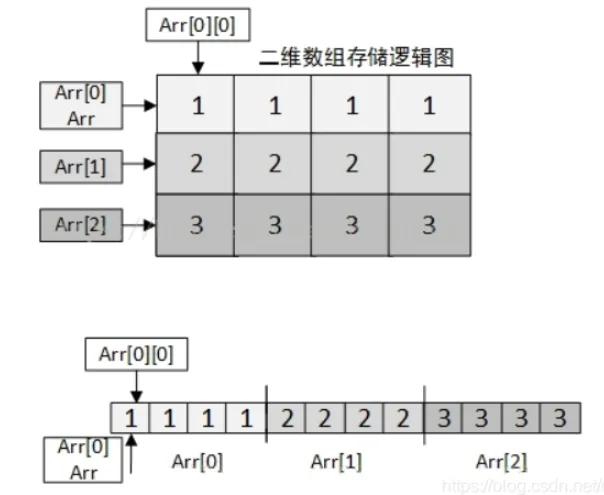
内存模型:按行优先存储
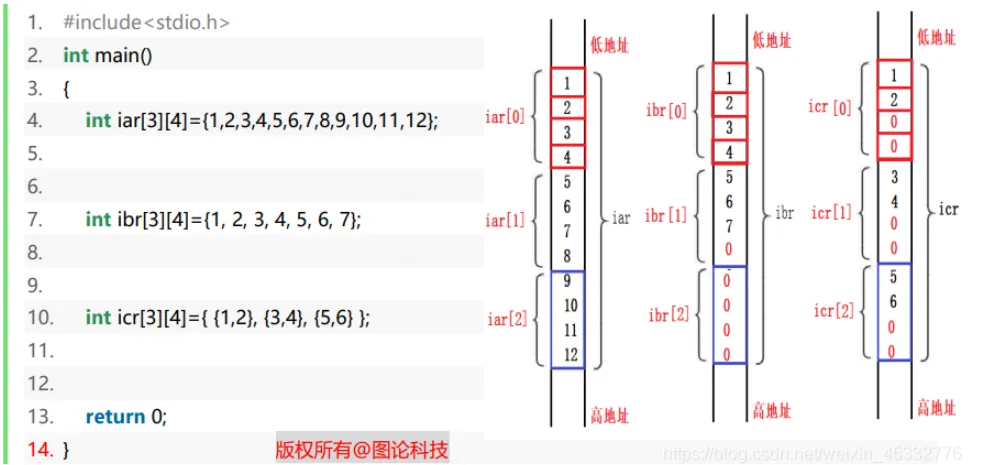
cint Arr [3] [4] = {{1,1,1,1},{2,2,2,2},{3,3,3,3},{4,4,4,4}};
数组地址+1
c// 一维数组
int a[5]={1,2,3,4,5};
int * ptr=(int*)(&a+1); // &a为整个数组的地址,&a+1为数组整体大小后移的位置
*(ptr-1) // 为数组最后一个元素的大小,=5
a++; // 非法,a虽然是指向数组首地址的指针,但其实际为cosnt类型,指针的指向无法改变
int* p = a; p++; // 这样合法
// 二维数组
int a[2][3] = {1,3,5,7,9,11};
**(a+1) = 7 // *(a+1)为a[0]+1,是第二行的首地址
双指针数组int **a[3][4]
c++int *z[3];
int **zz[3][4];
std::cout << sizeof(z) << std::endl;
std::cout << sizeof(zz) << std::endl;
//输出 3*8=24 与 4*24=96
int *array[10];
函数声明:void fun(int *a[10]);
函数调用:fun(array);
访问:使用*(a[i]+j)访问数组中的元素
int **array[10][20];
函数声明:void fun(int **a[10][20]);
函数调用:fun(array);
访问:(*(a+i) + j) 或者a[i][j]访问元素(使用双重指针表示的二维数组的访问方法)
[(22条消息) 二维数组与双重指针_Ven_J的博客-CSDN博客_双重指针数组](https://blog.csdn.net/Arcofcosmos/article/details/113645091)
二级指针
cvoid get(char** p, int num) {
*p = (char*)malloc(sizeof(char) * num);
}
char *str;
get(&str,10);
strcpy(str, "hello");
std::cout << str << std::endl;
cvoid get(char* p, int num) {
p = (char*)malloc(sizeof(char) * num);
}
char *str;
get(str,10);
strcpy(str, "hello");
std::cout << str << std::endl;
//ERROR
要改变指针指向的值,传入指针
要改变指针的指向,需要传入二级指针
register关键字
在 C++ 中,register 是一种关键字,用于建议编译器将变量存储在寄存器中,以提高访问速度。然而,需要注意的是,自 C++11 标准开始,register 关键字已经被弃用,编译器会忽略该建议。
在早期的 C++ 标准中,register 关键字可以用于声明变量,以提示编译器将其存储在寄存器中。寄存器是位于 CPU 内部的一种高速内存,可以更快地访问其中的数据,而不需要像访问内存地址那样的开销。通过存储在寄存器中,可以提高对变量的访问速度,从而提高程序的性能。
使用 register 关键字声明变量并不意味着变量一定会被存储在寄存器中,它只是向编译器提出了一个建议。编译器会根据具体的情况(如寄存器的可用性、变量的作用域等)决定是否将变量存储在寄存器中。如果编译器无法满足这个要求,那么该变量将按照通常的方式存储在内存中。
然而,需要注意的是,现代的编译器已经非常智能化,能够基于自身的优化算法和对代码的分析,自动决定何时将变量存储在寄存器中,而无需开发人员使用 register 关键字进行提示。因此,即使使用 register 关键字,编译器也可以忽略它,根据自身的优化策略来选择最佳的存储方式。
综上所述,register 关键字是一种用于建议编译器将变量存储在寄存器中的关键字,但自 C++11 标准开始已经被弃用,编译器会忽略它。现代编译器已经能够自动进行寄存器分配和优化,所以在实际编程中不再需要使用 register 关键字。
sizeof()
- sizeof 是在编译的时候,查找符号表,判断类型,然后根据基础类型来取值。
- 如果 sizeof 运算符的参数是一个不定长数组,则该需要在运行时计算数组长度。
字符设备与块设备
字符设备:操纵并读取硬件状态
块设备:存储功能,写入数据再读取,数据传输单位是扇区
extern”C” 的作用
实现C++中正确调用C编写的模块
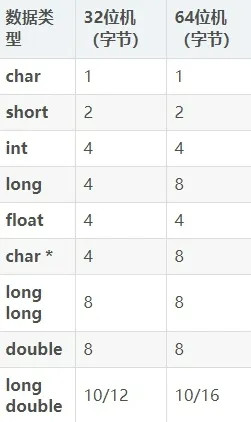
32Bit 64Bit区别
CPU 通用寄存器的数据宽度(CPU 一次能并行处理的二进制位数)
寻址能力(32Bit仅支持4GB寻址)
大小端
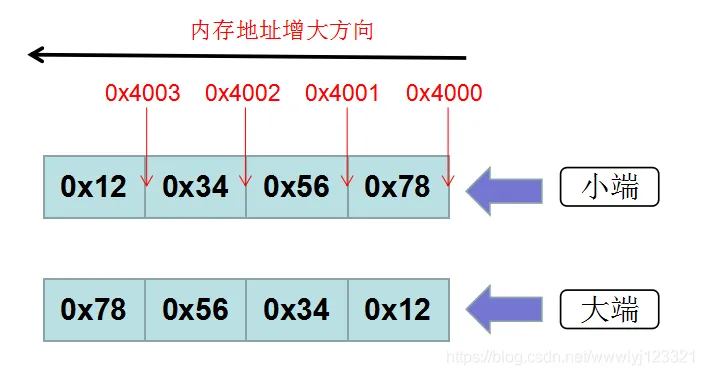
STM32:小端,低地址存放低位0x12345678:低->高78 56 34 12
| 大端 | 小端 | |
|---|---|---|
| 存储方式 | 高位存在低地址 | 高位存在高地址 |
| 内存排布0x12345678 | 低地址-高地址 | 低地址-高地址 |
| 12 34 56 78 | 78 56 34 12 |
 判断方法
判断方法
c#include<stdio.h>
union Un{
int a;
char b;
};
int is_little_endian1(void) {
union Un un;
un.a = 0x12345678;
if(un.b == 0x78) printf("小端\r\n");
else printf("大端\r\n");
}
int is_little_endian2(void) {
int a = 0x12345678;
char b = *((char *)(&a)); // 指针方式其实就是共用体的本质
if(b == 0x78) printf("小端\r\n");
else printf("大端\r\n");
}
转换方法
c// 变为u8类型数组后位移拼接
static inline uint32_t lfs_fromle32(uint32_t a) {
return (((uint8_t*)&a)[0] << 0) |
(((uint8_t*)&a)[1] << 8) |
(((uint8_t*)&a)[2] << 16) |
(((uint8_t*)&a)[3] << 24);
}
段错误
在LIinux 下C/C++中,出现段错误很多都是有指针造成的,段错误segmentation fault,信号SIGSEGV,是由于访问内存管理单元MMU异常所致,通常由于无效内存引用,如指针引用了一个不属于当前进程地址空间中的地址,操作系统便会进行干涉引发SIGSEGV信号产生段错误。
- 空指针(尝试操作地址为0的内存区域)
- 野指针(访问的内存不合法或无法察觉破坏了数据)
- 堆栈越界(同上)
- 修改了只读数据
为什么局部变量未定义时,每次初始化的结果是不确定的?
定义局部变量,其实就是在栈中通过移动栈指针,来给程序提供一个内存空间和这个局部变量名绑定。因为这段内存空间在栈上,而栈内存是反复使用的(脏的,上次用完没清零的) ,所以说使用栈来实现的局部变量定义时如果不初始化,里面的值就是一个垃圾值。
printf返回值
printf的返回值就是输出的字符数量‘
可变长度数组
VLA wariable length array
在C99中,允许在函数内部(栈空间)定义可变长度数组
c void test_func(int len) {
int arr[len];
arr[0] = 1; // 不可在定义时初始化
}
test_func(3);
变长结构体
在结构体中定义长度为0的数组,用以后续开辟变长buf,释放时仅释放结构体即可
c++#include <stdafx.h>
#include <iostream>
using namespace std;
const int BUF_SIZE = 100;
struct s_one {
int s_one_cnt;
char* s_one_buf; // 用指针指向不定长buf
};
struct s_two {
int s_two_cnt;
char s_two_buf[0]; // 用数组指向不定长buf
};
int main()
{
//赋值用
constchar* tmp_buf = "abcdefghijklmnopqrstuvwxyz";
int ntmp_buf_size = strlen(tmp_buf);
//<1>注意s_one 与s_two的大小的不同
cout<< "sizeof(s_one) = " << sizeof(s_one) << endl; //8
cout<< "sizeof(s_two) = " << sizeof(s_two) << endl; //4
cout<< endl;
//为buf分配100个字节大小的空间
int ntotal_stwo_len = sizeof(s_two) + (1 + ntmp_buf_size) * sizeof(char);
//给s_one buf赋值
s_one* p_sone = (s_one*)malloc(sizeof(s_one)); // 开辟结构体
memset(p_sone, 0, sizeof(s_one));
p_sone->s_one_buf = (char*)malloc(1 + ntmp_buf_size); // 开辟buf
memset(p_sone->s_one_buf, 0, 1 + ntmp_buf_size);
memcpy(p_sone->s_one_buf, tmp_buf, ntmp_buf_size);
//给s_two buf赋值
s_two* p_stwo = (s_two*)malloc(ntotal_stwo_len); // 开辟结构体
memset(p_stwo, 0, ntotal_stwo_len);
memcpy((char*)(p_stwo->s_two_buf), tmp_buf, ntmp_buf_size); //不用加偏移量,直接拷贝!
cout<< "p_sone->s_one_buf = " << p_sone->s_one_buf<< endl;
cout<< "p_stwo->s_two_buf = " << p_stwo->s_two_buf<< endl;
cout<< endl;
//<2>注意s_one 与s_two释放的不同!
if(NULL != p_sone->s_one_buf) { // 用指针保存需要释放两次
free(p_sone->s_one_buf); // 释放指针
p_sone->s_one_buf= NULL;
if(NULL != p_sone) {
free(p_sone); // 释放结构体
p_sone= NULL;
}
cout<< "free(p_sone) successed!" << endl;
}
if(NULL != p_stwo) { // 结构体保存释放一次
free(p_stwo); // 仅释放结构体
p_stwo= NULL;
cout<< "free(p_stwo) successed!" << endl;
}
return0;
}
CRC校验
循环冗余校验
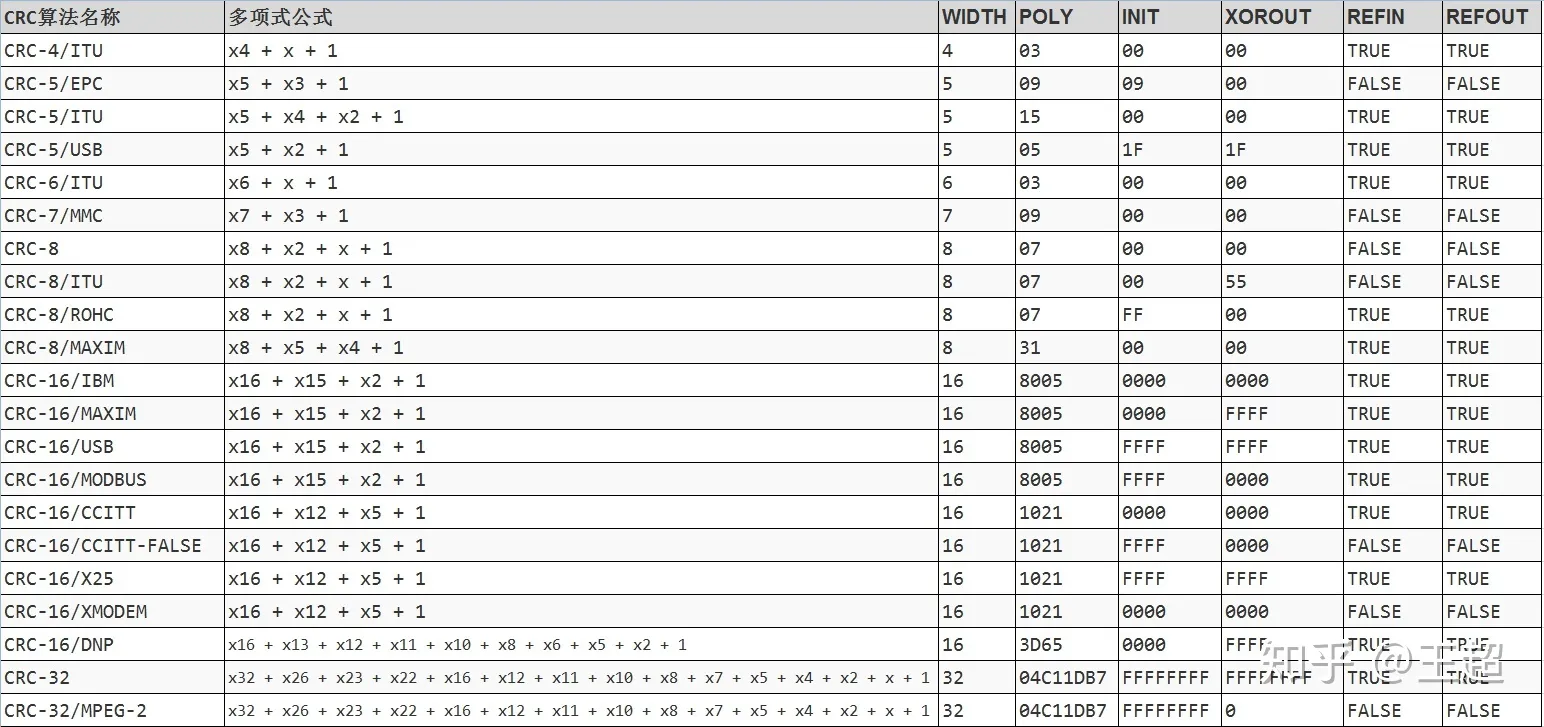
一个完整的CRC参数模型应该包含以下信息:WIDTH,POLY,INIT,REFIN,REFOUT,XOROUT。通常如果只给了一个多项式,其他的没有说明则:INIT=0x00,REFIN=false,REFOUT=false,XOROUT=0x00。
- NAME:参数模型名称。
- WIDTH:宽度,即生成的CRC数据位宽,如CRC-8,生成的CRC为8位
- POLY:十六进制多项式,省略最高位1,如 x8 + x2 + x + 1,二进制为1 0000 0111,省略最高位1,转换为十六进制为0x07。
- INIT:CRC初始值,和WIDTH位宽一致。
- REFIN:true或false,在进行计算之前,原始数据是否翻转,如原始数据:0x34 = 0011 0100,如果REFIN为true,进行翻转之后为0010 1100 = 0x2c
- REFOUT:true或false,运算完成之后,得到的CRC值是否进行翻转,如计算得到的CRC值:0x97 = 1001 0111,如果REFOUT为true,进行翻转之后为11101001 = 0xE9。
- XOROUT:计算结果与此参数进行异或运算后得到最终的CRC值,和WIDTH位宽一致。
 使用方法:
使用方法:
c#include "crcLib.h"
int main() {
uint8_t LENGTH = 10;
uint8_t data[LENGTH];
uint8_t crc;
for(int i = 0; i < LENGTH; i++) {
data[i] = i*5;
printf("%02x ", data[i]);
}
printf("\n");
crc = crc8_maxim(data, LENGTH);
printf("CRC-8/MAXIM:%02x\n", crc);
return 0;
}
c//crc8 generator polynomial:G(x)=x8+x5+x4+1
const unsigned char CRC8_INIT = 0xff;
const unsigned char CRC8_TAB[256] = {
0x00, 0x5e, 0xbc, 0xe2, 0x61, 0x3f, 0xdd, 0x83, 0xc2, 0x9c, 0x7 e, 0x20, 0xa3, 0xfd, 0x1f, 0x41,
0x9d, 0xc3, 0x21, 0x7f, 0xfc, 0xa2, 0x40, 0x1e, 0x5f, 0x01, 0xe3, 0xbd, 0x3e, 0x60, 0x82, 0xdc, 0x23,
0x7d, 0x9f, 0xc1, 0x42, 0x1c, 0xfe, 0xa0, 0xe1, 0xbf, 0x5d, 0x03, 0x80, 0xde, 0x3c, 0x62, 0xbe, 0xe0,
0x02, 0x5c, 0xdf, 0x81, 0x63, 0x3d, 0x7c, 0x22, 0xc0, 0x9e, 0x1d, 0x43, 0xa1, 0xff, 0x46, 0x18, 0xfa,
0xa4, 0x27, 0x79, 0x9b, 0xc5, 0x84, 0xda, 0x38, 0x66, 0xe5, 0xbb, 0x59, 0x07, 0xdb, 0x85, 0x67,
0x39, 0xba, 0xe4, 0x06, 0x58, 0x19, 0x47, 0xa5, 0xfb, 0x78, 0x26, 0xc4, 0x9a , 0x65, 0x3b, 0xd9, 0x87,
0x04, 0x5a, 0xb8, 0xe6, 0xa7, 0xf9, 0x1b, 0x45, 0xc6, 0x98, 0x7a, 0x24, 0xf8, 0xa6, 0x44, 0x1a, 0x99,
0xc7, 0x25, 0x7b, 0x3a, 0x64, 0x86, 0xd8, 0x5b, 0x05, 0xe7, 0xb9,
0x8c, 0xd2, 0x30, 0x6e, 0xed, 0xb3, 0x51, 0x0f, 0x4e, 0x10, 0 xf2, 0xac, 0x2f, 0x71, 0x93, 0xcd, 0x11,
0x4f, 0xad, 0xf3, 0x70, 0x2e, 0xcc, 0x92, 0xd3, 0x8d, 0x6f, 0x31, 0xb2, 0xec, 0x0e, 0x50, 0xaf, 0xf1,
0x13, 0x4d, 0xce, 0x90, 0x72, 0x2c, 0x6d, 0x33, 0xd1, 0x8f, 0x0c, 0x52, 0xb0, 0xee, 0x32, 0x6c, 0x8e,
0xd0, 0x53, 0x0d, 0xef, 0xb1, 0xf0, 0xae, 0x4c, 0x12, 0x91, 0xcf, 0x2d, 0x73, 0xca, 0x94, 0x76, 0x28,
0xab, 0xf5, 0x17, 0x49, 0x08, 0x56, 0xb4, 0xea, 0x69, 0x37, 0xd5, 0x8b, 0x57, 0x09, 0xeb, 0xb5,
0x36, 0x68, 0x8a, 0xd4, 0x95, 0xcb, 0x29, 0x77, 0xf4, 0xaa, 0x48, 0x1 6, 0xe9, 0xb7, 0x55, 0x0b, 0x88,
0xd6, 0x34, 0x6a, 0x2b, 0x75, 0x97, 0xc9, 0x4a, 0x14, 0xf6, 0xa8,
0x74, 0x2a, 0xc8, 0x96, 0x15, 0x4b, 0xa9, 0xf7, 0xb6, 0xe8, 0x0a, 0x54, 0xd7, 0x89, 0x6b, 0x35,
}
// 计算CRC值
unsigned char Get_CRC8_Check_Sum(unsigned char *pchMessa ge, unsigned int dwLength, unsigned char ucCRC8) {
unsigned char ucIndex;
while (dwLength --) {
ucIndex = ucCRC8^(*pchMessage++);
ucCRC8 = CRC8_TAB[ucIndex];
}
return(ucCRC8);
}
// 验证CRC值
/*
** Descriptions: CRC8 Verify function
** Input: Data to Verify,Stre am length = Data + checksum
** Output: True or False (CRC Verify Result)
*/
unsigned int Verify_CRC8_Check_Sum(unsigned char *pchMessage, unsigned int dwLength) {
unsigned char ucExpected = 0;
if ((pchMessage == 0) || (dwLength <= 2)) return 0;
ucExpected = Get_CRC8_Check_Sum (pchMessage, dwLength 1, CRC8_INIT);
return ( ucExpected == pchMessage[dwLength-1] );
}
/*
** Descriptions: append CRC8 to the end of data
** Input: Data to CRC and append,Stream length = Data + checksum
** Output: True or False (CRC Verify Result)
*/
void Append_CRC8_Check_Sum(unsigned char *pchMessage, unsigned int dwLength) {
unsigned char ucCRC = 0;
if ((pchMessage == 0) || (dwLength <= 2)) return;
ucCRC = Get_CRC8_Check_Sum ( (unsigned char *)pc hMessage, dwLength 1, CRC8_INIT);
pchMessage[dwLength 1] = ucCRC;
uint16_t CRC_INIT = 0xffff;
}
奇偶校验
如果数据中1的个数为奇数,则奇校验位0,否则为1
例:1101中,1有3个,校验码为0
静态链接与动态链接
静态库在链接阶段的进行组合,动态库在运行时加载
静态链接生成的可执行文件体积较大,消耗内存,如果所使用的静态库发生更新改变,程序必须重新编译
- 静态库的链接是将整个函数库的所有数据在编译时都整合进了目标代码,最小单位是文件,因此空间浪费,更新困难
- 动态库的链接是程序执行到哪个函数链接哪个函数的库
动态链接库编译时的操作:
我们在形成可执行程序时,发现引用了一个外部的函数,此时会检查动态链接库,发现这个函数名是一个动态链接符号,此时可执行程序就不对这个符号进行重定位,而把这个过程留到装载时再进行。
- 静态链接(Static Linking):
- 在编译时将所有的函数和库代码合并成一个可执行文件。
- 链接是在编译段完成的,链接库和目标代码中提取所需的函数和库代码,将它们合并到最终的执行文件中 - 链接结果是一个独立的、完的可执行文件,包含了所有依赖的函数和库代码。
- 优点:
- 执行速度快,为所有代码已经被编译和链接在一起,无需运行时动态加载额外的库文件。
- 可执行文件独立,可以在没有安装相应库文件的系统上运行。
- 缺点:
- 可执行文件较,因为所有依赖的函数和库代码都被静态链接到可执行文件中。
- 更新和替换依赖的函数和库代码需要重新编译和链接整个程序。
- 动态链接(Dynamic Linking):
- 在运行通过动态链接库在内存中加载所需的函数和库代码。
- 链接是在运行时完成的,链接器在运程序时动态加载所需的函数和库代码。
- 链接结果是一个可执行文件和一个或多个动态链接库,可执行文件只包含必要的启动代码和符号引用。
- 优点:
- 可执行文件较小,因为只包含必要的启动代码和符号引用。
- 动态链接库可以在多个可文件之间共享,节省内存空间。
- 更新和替换依赖的函数和库代码只需要替换对应的动态链接库。
- 缺点:
- 相对于静态链接,运行时需要额外的时间加载和解析动态链接库。 -中必须存在相应的动态链接库文件,否则程序无法运行。
总说,静态链接将所有的函数和库代码合并到一个可执行文件中,执行速度快,但可执行文件较大;而动态链接在运行时加载所需的函数和库代码,可执行文件较小,但可能需要额外的加载时间依赖系统存在相应的动态链接库文件。选择使用哪种方式取决于项目的需求和考虑的因素。
数据结构
二叉树遍历方式
- 先(根)序遍历(根左右)
- 中(根)序遍历(左根右)
- 后(根)序遍历(左右根)
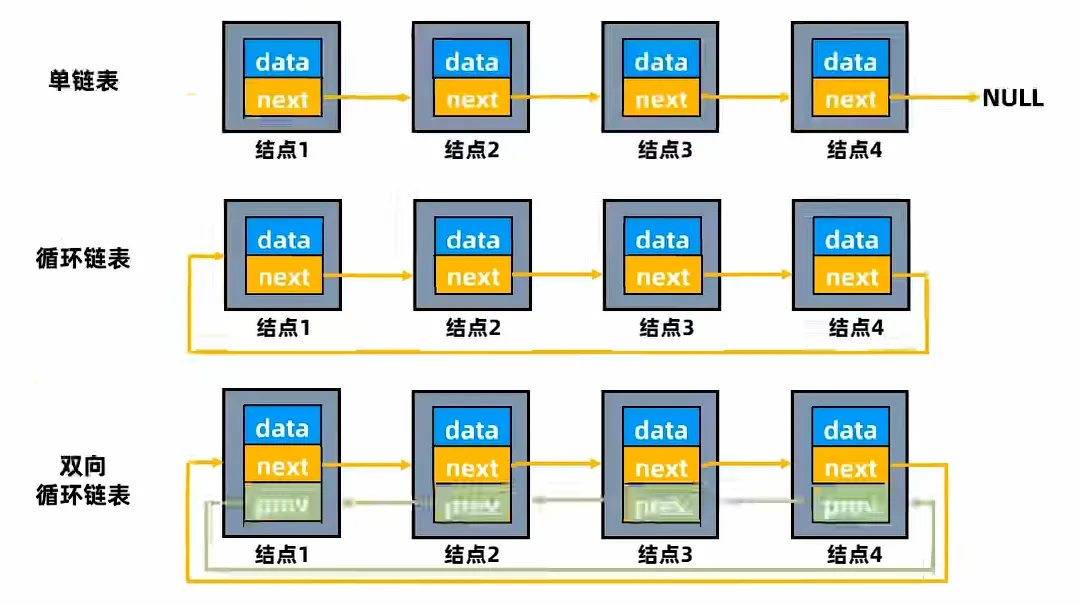
链表操作
环形缓冲 循环队列
- 作用:FIFO,且写入数据为短时间大量,读取为低速少量但高频
- (平均读取速度一定要高于写入速度,否则多大的buf都会满)
- 主要构成:起始位置、长度、读位置、写位置
方法1:采用镜像指示位,读写越界时翻转镜像指示位
初始均为0,空;放入5个数据,读位置0不变,写位置+5后变为0+5=5
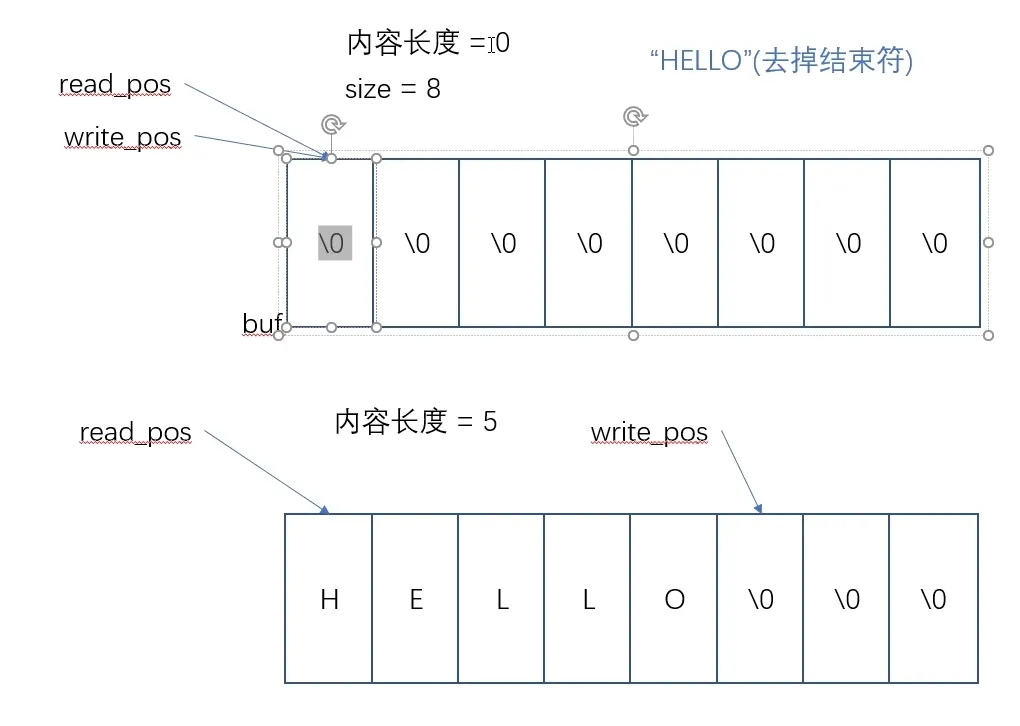 尝试再次写入5个数据
尝试再次写入5个数据
此时镜像指示位write_mirror置1,表示越界了,同时读写指针均为0,表示满了
 方法2:少利用一块数据区域,读写指针相等为空,写指针+1==读指针为满
方法2:少利用一块数据区域,读写指针相等为空,写指针+1==读指针为满
ring buffer,一篇文章讲透它? - 掘金 (juejin.cn)

c//队列为满的条件
(rear+1) % MaxSize == front;
//队列为空的条件
front == rear;
// 队列中元素的个数
(rear- front + maxSize) % MaxSize;
//入队
rear = (rear + 1) % maxSize;
// 出队
front = (front + 1) % maxSize;
当涉及到多线程时采用信号量通知,加锁互斥访问
通信协议
对比
| 协议 | 通信速率 | 优劣 | 工作模式 | 模块数量 | 接口数量 | 时序图 |
|---|---|---|---|---|---|---|
| UART | 115200 bit/s 约100 Kbit/s | 优势:双线制,全双工 劣势:时序要求严格,速率低 | 全双工,异步(依据约定波特率采样) | 一对一 | TX、RX | 起始位低电平,数据位8 bit(每Byte数据先发送低位),停止位以及空闲高电平,一帧10 bit  |
| 232 | 优势:规定了电气特性 劣势:传输距离15m,速率低 | 同UART | 一对一 | |||
| 485 | 优势:规定了电气特性,可组网,传输距离远1500m 劣势:半双工 | 半双工 | 一对多 | A、B |  | |
| IIC | 100或400 Kbit/s | 优势:双线制,低成本,有应答。 劣势:通信速率低,半双工,通信距离短 | 半双工,同步(起始信号,应答信号,结束信号) | 多主多从(谁控制时钟线谁为主设备)(器件地址唯一) | SDA、SCLK | 每Byte数据先发送高位,一帧9bit,SCLK(高电平读取,低电平发送)  |
| SPI | 10到150 Mbit/s | 优势:全双工高速,数据长度不限。 劣势:从机无应答信号,引脚较多,通信距离短 | 全双工,同步(拉低片选,依据时钟沿采样) | 一主多从(一、多根互斥的CS片选)(二、菊花链) | SCK、MOSI、MISO、CS | 每Byte数据先发送高位,帧长不限  |
| CAN | bx CAN:1Mbit/s CAN FD:8Mbit/s | 优势:差分电平通信距离长。 劣势:速率低带宽小 | 半双工 | 不分主从 | CANH、CANL |   |
UART
空闲时间总线高电平,起始位1bit拉低,数据位8bit,停止位1bit拉高
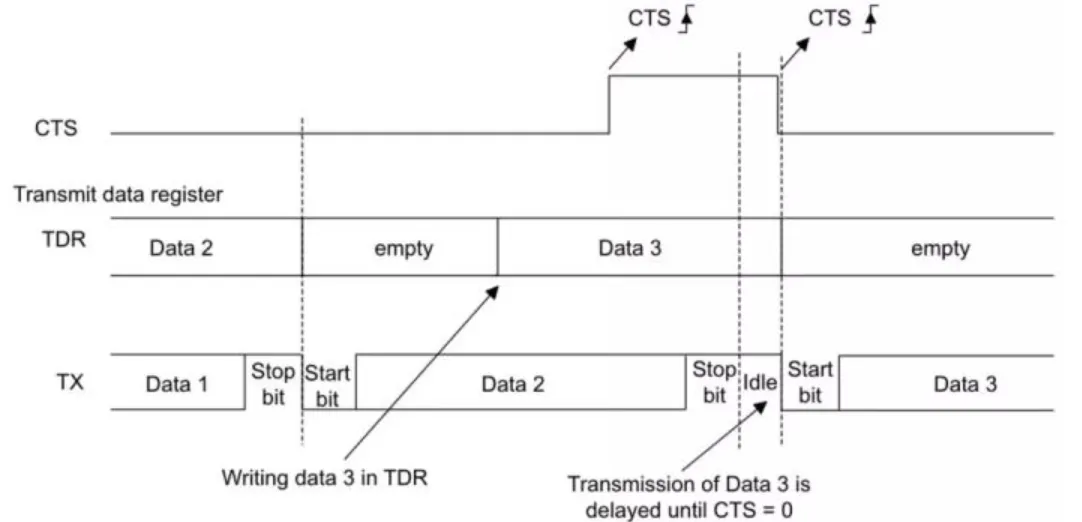
流控
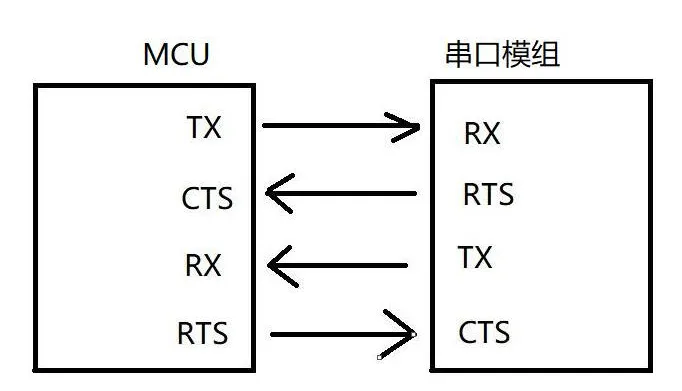
作用:当通信双方处理速度不一致时
接收方:通过RTS告知对方自己正在处理,占用时拉高(发送方等待),空闲时拉低(发送方发送)
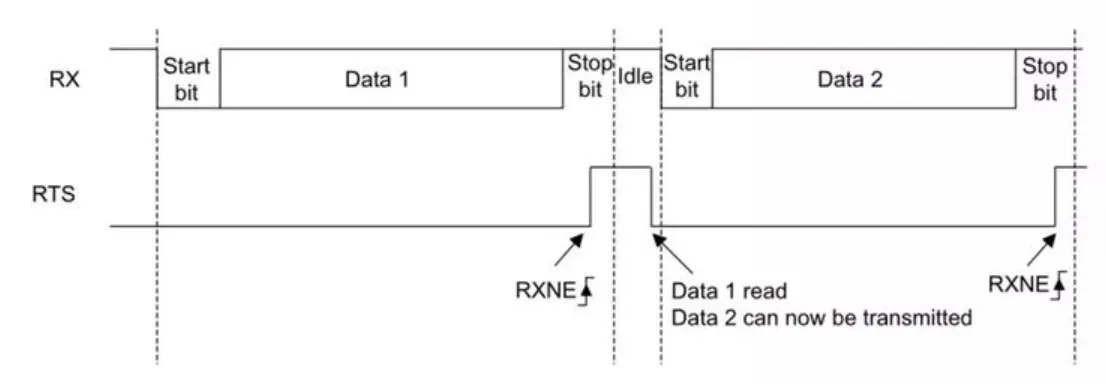
发送方:判断CTS信号,拉低时发送
TTL
供电范围在0~5V;>2.7V是高电平;<0.5V是低电平
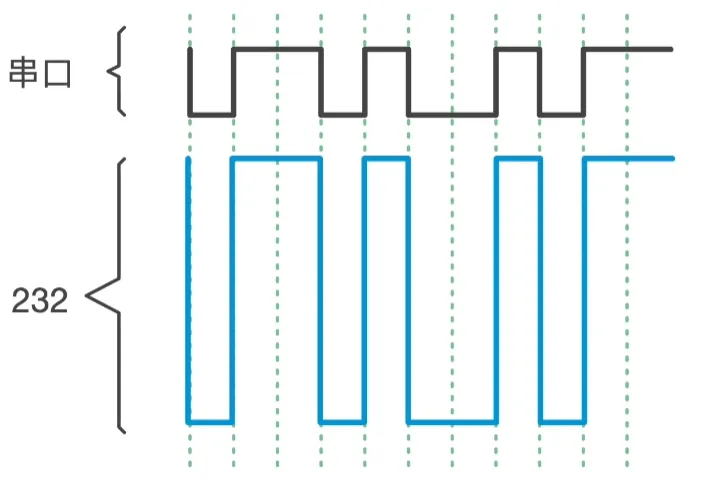
RS232
±15V
负电平表示逻辑"1",正电平表示逻辑"0",通过提高电压差的方式抗干扰
- 负电平范围为-3V至-15V
- 正电平范围为+3V至+15V
RS485
±6V
通过差分信号抗干扰,当A线高于B线时,表示逻辑"1";当B线高于A线时,表示逻辑"0"。
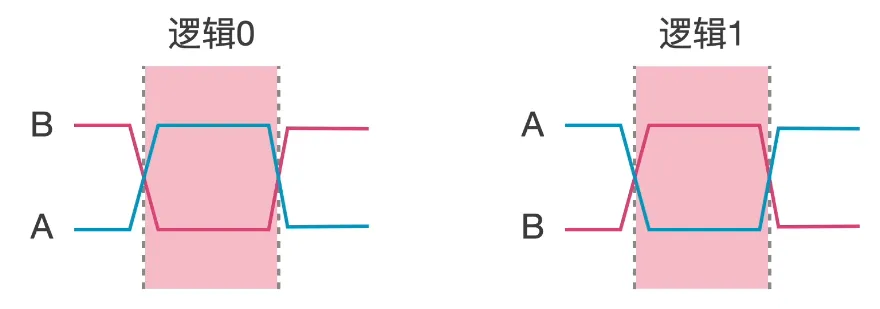
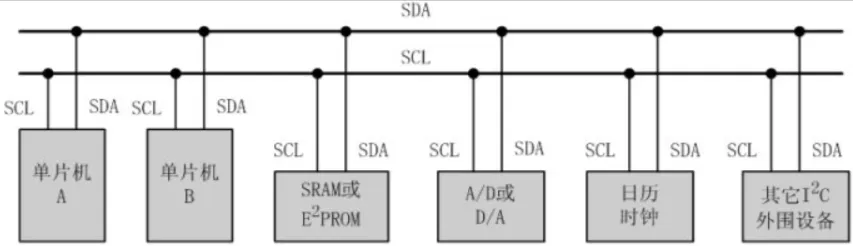
IIC
- 总线空闲时,SCLK与SDA均为高电平
- 连接到总线上的任一器件,输出低电平,都将使总线的信号变低。
- 连接总线的器件输出级必须是集电极或漏极开路,以形成线“与”功能。
- 每个具有IIC接口的设备都有一个唯一的地址,也叫做设备地址,通讯时需要进行寻址。
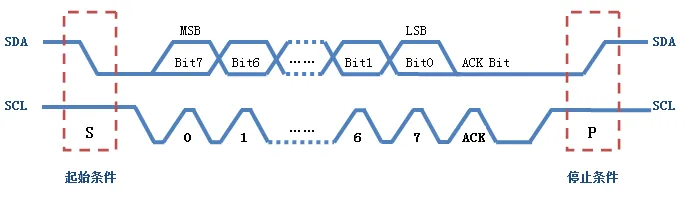
 开始信号:SCL 为高电平时,SDA 由高电平向低电平跳变,开始传送数据。(SDA先拉低)
结束信号:SCL 为高电平时,SDA 由低电平向高电平跳变,结束传送数据。(SCL先拉高)
应答信号:每当主机发送完1Byte,总要等待从机给出1bit的应答信号,以确认从机是否成功接收到了数据(主机SCL拉高,读取从机SDA的低电平为应答)
开始信号:SCL 为高电平时,SDA 由高电平向低电平跳变,开始传送数据。(SDA先拉低)
结束信号:SCL 为高电平时,SDA 由低电平向高电平跳变,结束传送数据。(SCL先拉高)
应答信号:每当主机发送完1Byte,总要等待从机给出1bit的应答信号,以确认从机是否成功接收到了数据(主机SCL拉高,读取从机SDA的低电平为应答)
采样点:稳态电平采样
当SCL=1高电平时进行数据采样,数据线SDA不允许有电平跳变,否则视为开始与停止信号
通信过程:
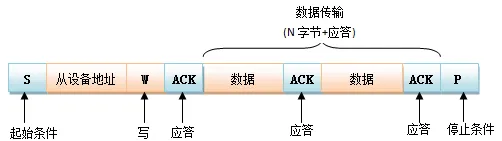
- 主机发送起始信号
- 主机发送1Byte(从机地址+后续数据传送方向)每个器件具有唯一地址7bit,数据方向:0写1读
- 从机发送应答信号1bit
- 发送方与接收方相继发送1Byte+应答信号
- 主机发送结束信号
写时序
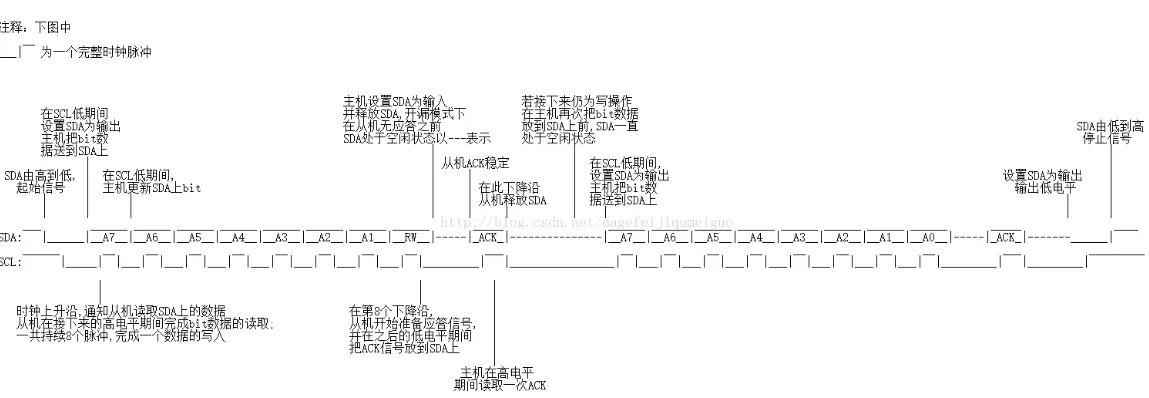
读时序
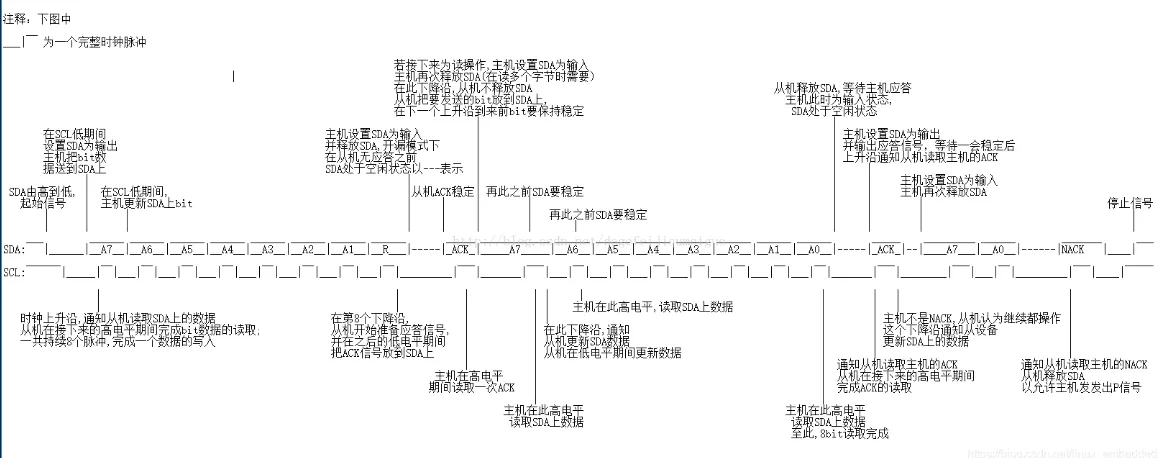
冲突检测与仲裁:(发送方监测,发送电平与SDA电平不符时关闭输出)
-
一种简单的预防冲突机制是:设备在发送数据之前,需要进行冲突检测,检测的依据就是检查SDA的电平状态:只要检测到SDA为低电平,那就是表示总线处于被占用的状态,那么,为了避免发生冲突,当前设备必须等待一段时间以后再次去检测SDA的电平状态,如果总线变成“空闲”的了(即SDA为高电平),那么该设备才能进行通信。
-
这里有一个关键点就是:如何保证连接到I2C总线上的多个的设备,只要存在一个设备占用了总线,其他设备无论如何也不能使总线变为空闲呢?上文说的集电极开路结构就能达到这个要求。
-
每个设备的SDA输出的值,不完全相同,但是,只要有一个为“0”,其结果就是“0”,这就是线与,其可以保证SDA线上的信号,要么稳定为“0”(至少一个设备输出为0),要么稳定为“1”(全部设备输出都为1)。
主机代码
c//总线启动条件
void IIC_Start(void) {
SDA = 1;
SCL = 1;
IIC_Delay(DELAY_TIME);
SDA = 0;
IIC_Delay(DELAY_TIME);
SCL = 0;
}
//总线停止条件
void IIC_Stop(void) {
SDA = 0;
SCL = 1;
IIC_Delay(DELAY_TIME);
SDA = 1;
IIC_Delay(DELAY_TIME);
}
//通过I2C总线发送数据
void IIC_SendByte(unsigned char byt) {
unsigned char i;
for(i=0; i<8; i++)
{
SCL = 0;
IIC_Delay(DELAY_TIME);
if(byt & 0x80)
SDA = 1;
else
SDA = 0;
IIC_Delay(DELAY_TIME);
SCL = 1;
byt <<= 1; //从最高位开始传输数据
IIC_Delay(DELAY_TIME);
}
SCL = 0;
}
//等待应答
bit IIC_WaitAck(void) {
bit ackbit;
SDA = 1; //新加,释放数据总线,若被从机拉低证明ACK数据有效
IIC_Delay(DELAY_TIME);
SCL = 1;
IIC_Delay(DELAY_TIME);
ackbit = SDA;
if(ackbit) //新加,若无应答,则停止总线
IIC_Stop();
SCL = 0;
IIC_Delay(DELAY_TIME);
return ackbit;
}
从机代码
c//从机发送应答
void IIC_SendAck(bit ackbit) {
SCL = 0;
SDA = ackbit; // 0:应答,1:非应答
IIC_Delay(DELAY_TIME);
SCL = 1;
IIC_Delay(DELAY_TIME);
SCL = 0;
SDA = 1;
IIC_Delay(DELAY_TIME);
}
//从I2C总线上接收数据
unsigned char IIC_RecByte(void) {
unsigned char i, da;
for(i=0; i<8; i++)
{
SCL = 1;
IIC_Delay(DELAY_TIME);
da <<= 1; //从高位开始接受数据
if(SDA)
da |= 1;
SCL = 0;
IIC_Delay(DELAY_TIME);
}
return da;
}
IIC从机地址配置方式
-
内部固定地址:某些 I2C 从机设备具有内部固定的从机地址,无法进行配置或更改。在这种情况下,从机地址是设备制造商预定义的。
-
硬件引脚配置:一些 I2C 从机设备具有专用引脚或引脚配置选项,用于设置从机地址。通过使用跳线帽、电阻、芯片的引脚配置等方式,用户可以将特定的引脚配置为高电平或低电平,从而设置从机地址。
-
寄存器配置:一些 I2C 从机设备允许使用特殊的寄存器配置来设置从机地址。这通常通过主机和从机之间的特殊序列和命令来实现。
IIC地址交换
运行过程中,如果新的IIC设备接入,主机和从机如何交换地址?
- 主机发送广播地址(遍历所有预定义的地址进行扫描),等待应答
- 从机监听到自己地址后进行应答
IIC最大设备数量
I2C 协议使用地址来选择特定的从设备进行通信。每个从设备都有一个唯一的 7 位或 10 位地址。
在 I2C 协议中,最多可以有 128 个 7 位地址设备和 1024 个 10 位地址设备。但实际可连接的设备数量受制于总线负载和电气特性等因素。
SPI
四种模式:
时钟极性(CPOL)定义了时钟空闲状态电平:
- CPOL=0,表示当SCLK=0时处于空闲态,所以有效状态就是SCLK处于高电平时
- CPOL=1,表示当SCLK=1时处于空闲态,所以有效状态就是SCLK处于低电平时
时钟相位(CPHA)定义数据的采集时间。
- CPHA=0,在时钟的第一个跳变沿(上升沿或下降沿)进行数据采样。,在第2个边沿发送数据
- CPHA=1,在时钟的第二个跳变沿(上升沿或下降沿)进行数据采样。,在第1个边沿发送数据
| mode | CPOL | CPHA | 描述 |
|---|---|---|---|
| mode 0 | 0 | 0 |  |
| mode 1 | 0 | 1 |  |
| mode 2 | 1 | 0 |  |
| mode 3 | 1 | 1 |  |
一主多从时的连接:(多CS)(菊花链)
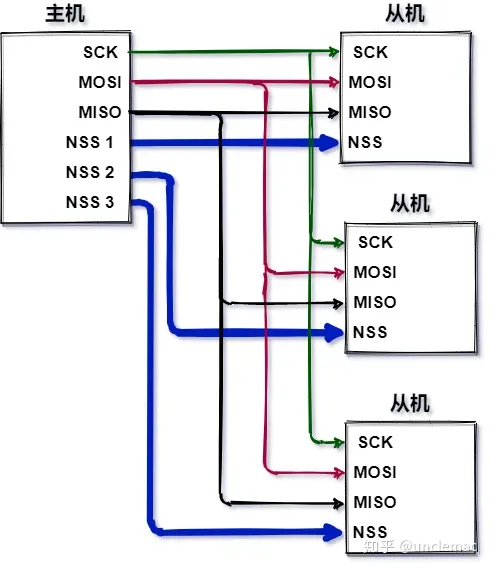
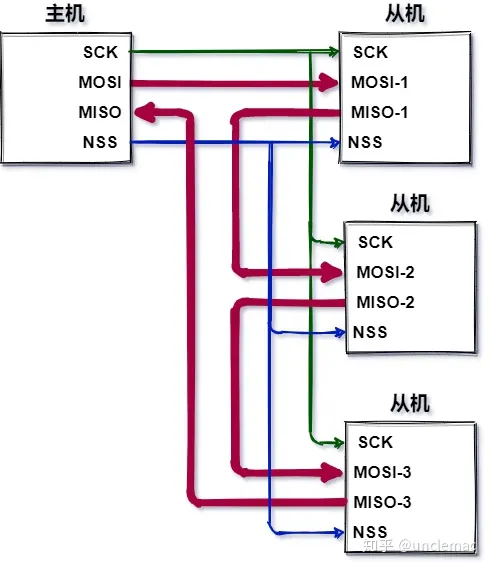
软件SPI与硬件SPI:
- 软件SPI用GPIO口的电平变化模拟SPI通信时序,移植性好,占用CPU资源,速度慢
- 硬件SPI用HAL库封装的HAL_SPI_Transmit即可,占用CPU资源少,速度快,但对PCB走线有要求
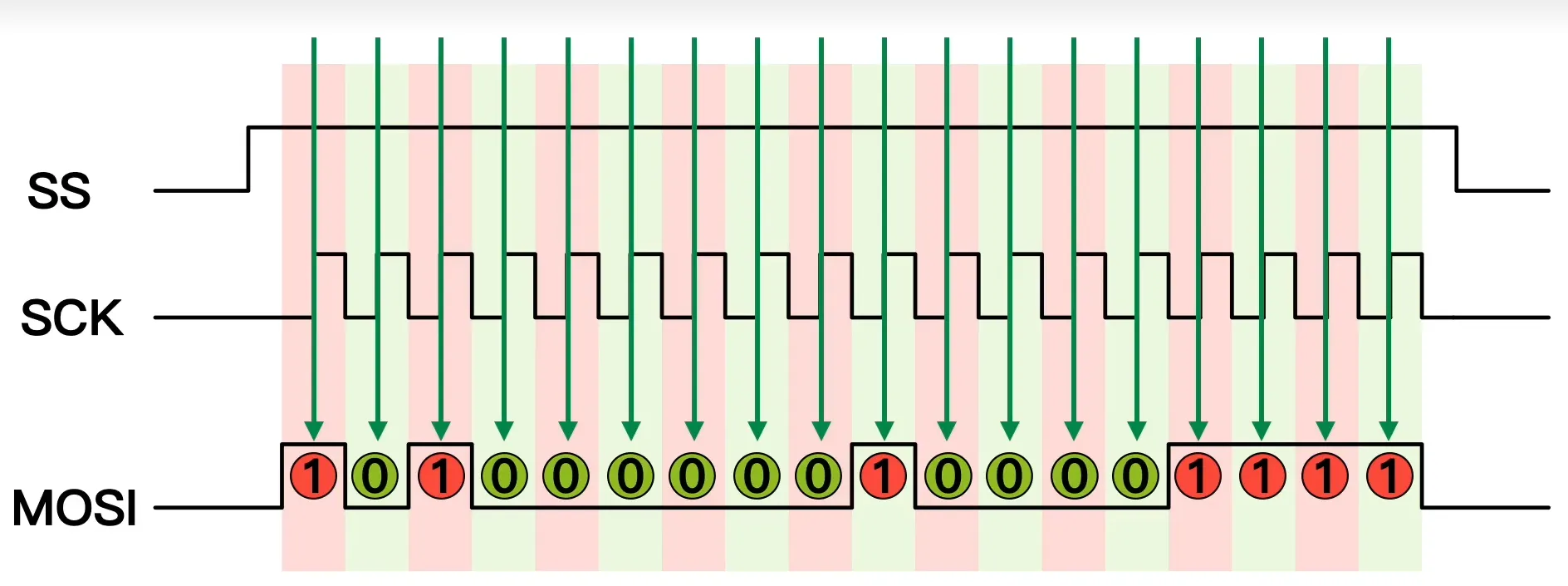
采样点:边沿采样
SPI接口的一个缺点:没有指定的流控制,没有应答机制确认是否接收到数据。
CAN
物理层:两条线差分电平0~5 V,CAN H电压高于CAN L为显性电平(逻辑0),采用CAN收发器将TX RX电平转换为差分,各设备采用ID号区分
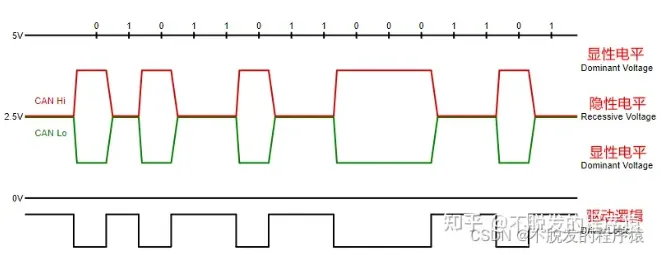
标准: bx CAN 2.0 b: 1 Mbps,每帧8 Byte带CRC
CAN FD: 8 Mbps,每帧64 Byte
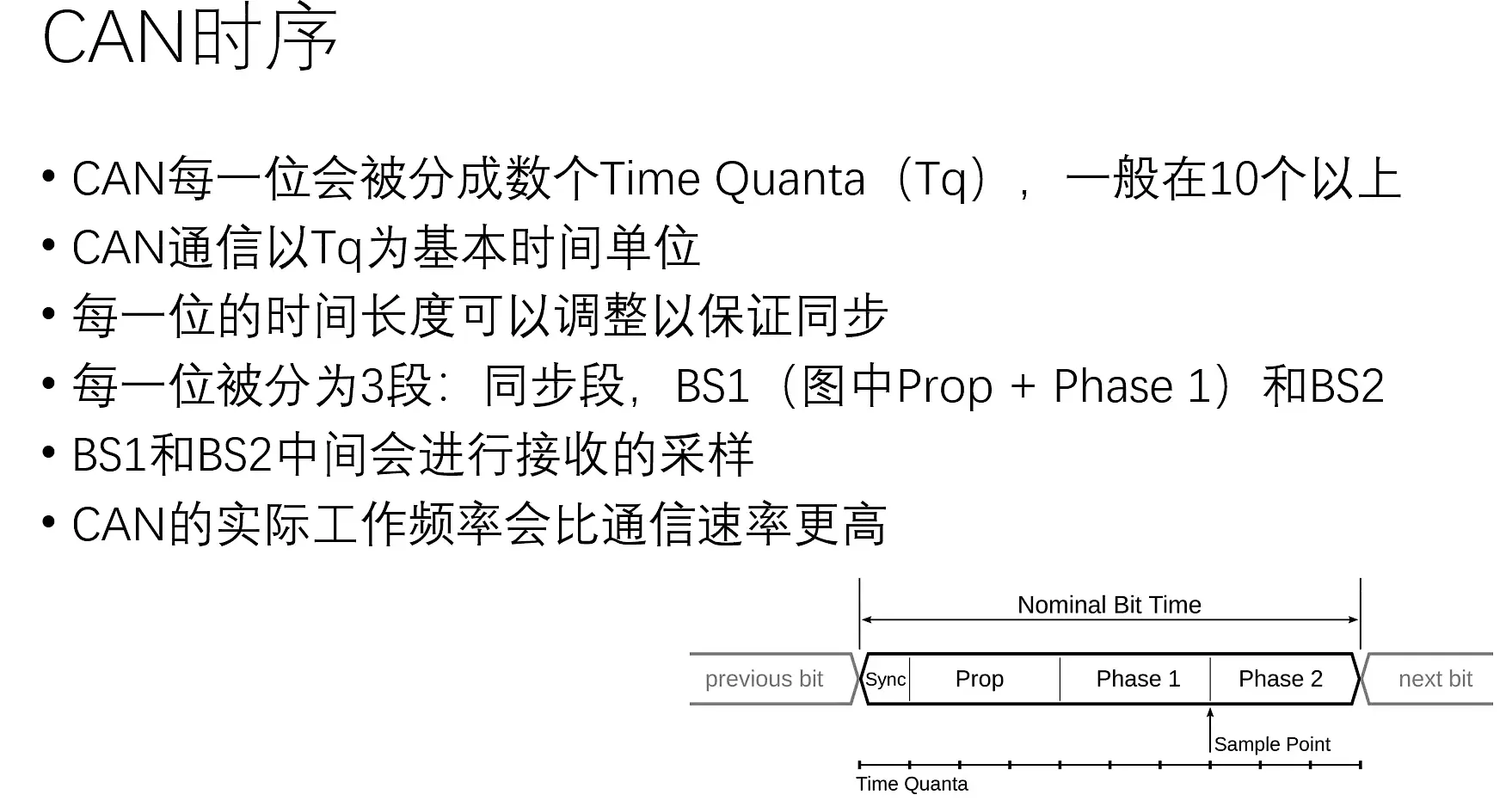
时序:保证总线上各设备时钟不同步情况下,通信是同步的,将1 Bit分为三段再分为多个Tq

数据帧:存在连续5个以上相同位,帧中需要插入一个相反的位(stuff bit)

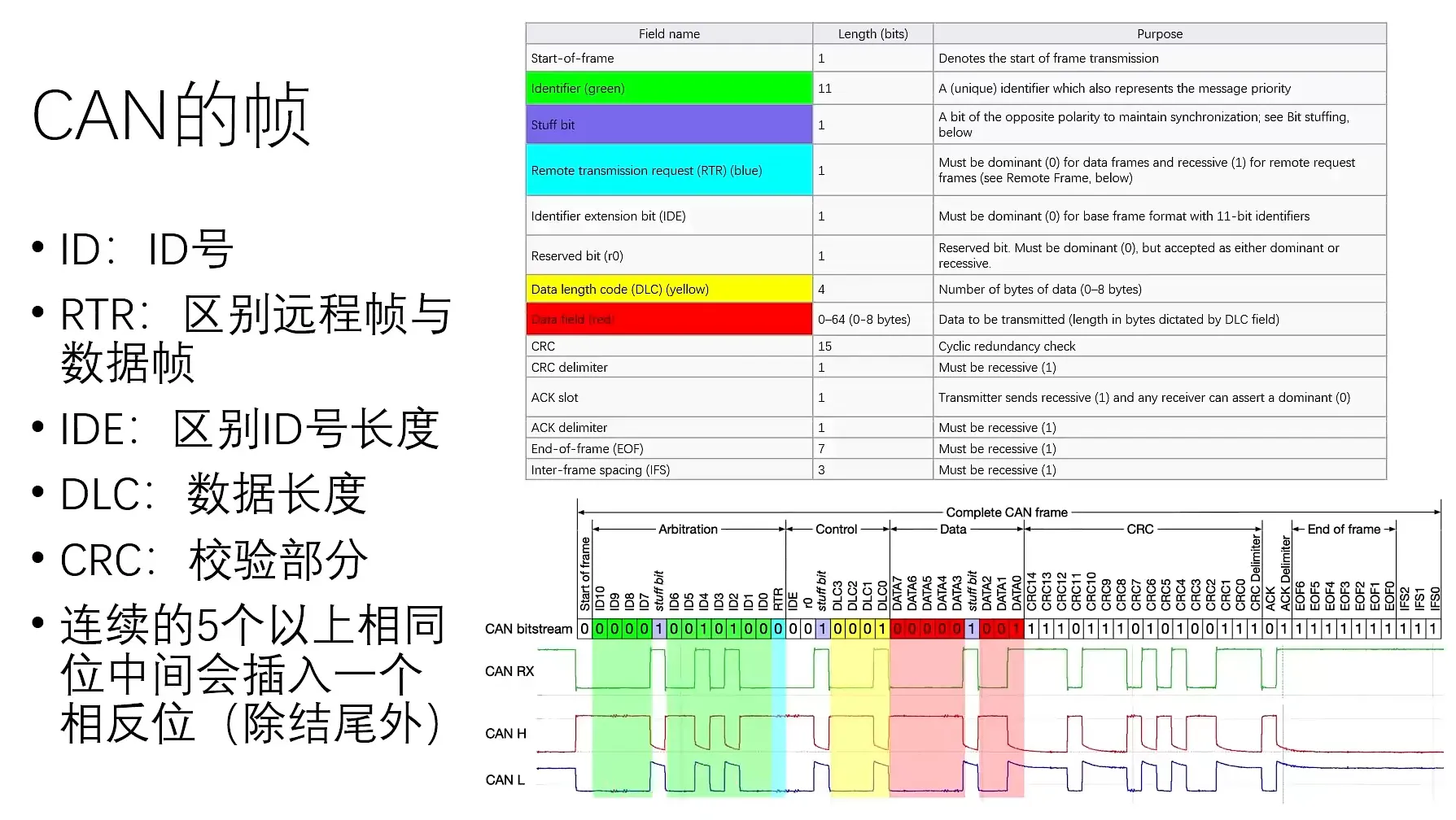
仲裁:CAN 为半双工,不可同时收发,依据ID号中的0的数量进行仲裁

STM32 CAN结构:

过滤器:实际使用中采用列表模式,资源紧张时采用掩码模式

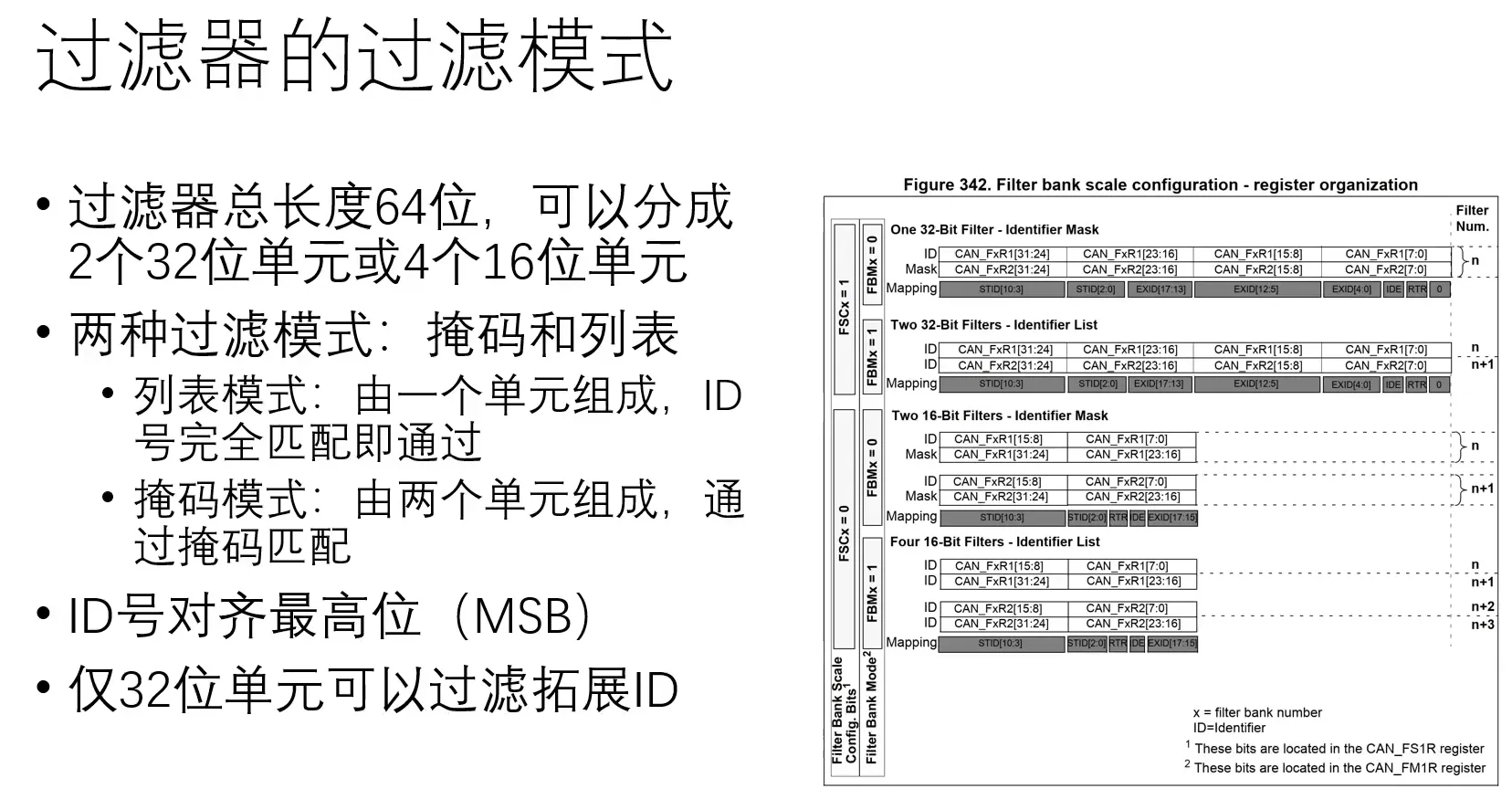

此处有误,应是0x00 0x1FF与0x100掩码,按位与为1的位需要匹配,为0的位不滤除
双接收中断FIFO:
每当收到一个报文,CAN就将这个报文先与FIFO_0关联的过滤器比较,如果被匹配,就将此报文放入FIFO_0中。如果不匹配,再将报文与FIFO_1关联的过滤器比较,如果被匹配,该报文就放入FIFO_1中。如果还是不匹配,此报文就被丢弃

CAN最多可以挂载110个节点,依据总线负载率<70%
内存
内存模型 data bss heap stack
- Flash = Code + RO-data + RW-data
- RAM = RW-data + ZI-data
内存四区:代码区,全局区,堆区,栈区
| 地址 | 区域 | 内容 | 存放位置 | 举例 |
|---|---|---|---|---|
| 0x0000 | .text 代码段 | 编译后的机器码 | Flash | #define ro_def 0x11111111UL |
| .ROdata | 只读常量 | Flash | const uint32_t ro_var = 0x22222222; | |
| .RWdata 已初始化 | 静态变量、全局变量,启动时从Flash读取已初始化数据搬运到RAM | RAM | int global_var= 123; static int c = 0; | |
| .bss 未初始化 | 全局变量,启动时,自动初始化为0 | RAM | int global_var; | |
| .heap 堆 | 动态内存分配,程序员手动开辟释放,向↓增长 | |||
| ---------- | ||||
| 0xFFFF | .stack 栈 | 函数局部变量,由编译器开辟释放,向↑增长 |
初始化过程:数据一开始都存储与ROM中,其中包含RO DATA(常量)、text(代码)、RW DATA(先存储于flash,上电后搬运到RAM)。RAM:加载来自于ROM 的 RW DATA,随后依据启动文件初始化ZI DATA为0
数组下标越界
cint arr[5];
arr[-1]; // 可能可以正常执行
arr[5]; // 一定报错
由于函数栈的增长方向为高地址->低地址,高地址处存放函数返回信息和比数组先存入的信息,并且数组的存储顺序为下标小的元素在低地址,因此往高地址越界时会改写原本栈中的数据,往低地址越界修改的是空的未使用的栈,可能不出问题。
解决方案:利用assert和迭代器来避免
MCU采用 XIP(eXecute In Place)的方式在 Flash 中运行程序,而不是搬运到 RAM 中
- 节省内存空间:MCU 往往具有较小的内存容量,特别是 RAM 的容量较有限。使用 XIP 可以避免将程序复制到 RAM 中造成内存空间的占用,从而节省了宝贵的 RAM 空间,可以将 RAM 用于其他需要快速存取的数据。
- 成本优势:RAM 往往比 Flash 的价格更高,因此将程序直接运行在 Flash 中可以降低系统成本。在 MCU 中,Flash 往往是固化在芯片内部的,而 RAM 需要额外的外部芯片或部件支持,增加了系统的复杂性和成本。
- 提高读取速度:Flash 存储器通常具有较快的访问速度,对于微控制器来说,执行程序时可能已经足够快。在 XIP 模式下,不需要将程序从 Flash 复制到 RAM,节省了在复制过程中的时间,可以直接在 Flash 中运行,加快了程序的启动时间和响应速度。
- 适用于嵌入式系统:MCU 往往嵌入在一些资源受限、功耗要求较低的嵌入式系统中。使用 XIP 可以减少对外部 RAM 的需求,降低功耗,并且提高系统整体的稳定性和可靠性。
尽管 XIP 有以上的优势,它仍然存在一些限制和考虑因素,例如访问延迟较高、不适用于频繁写操作的场景等。因此在设计 MCU 的时候需要综合考虑具体的应用场景和需求来选择合适的存储方案。
Linux栈一般多大
- Linux栈的大小可以在编译内核时进行配置,并且可以根据系统需求进行调整。栈的大小决定了每个线程的可用栈空间大小。
- 在大多数Linux系统上,默认的栈大小为8MB。但是,这个值并不是固定的,可以通过修改内核参数或使用特定的命令来改变栈的大小。
为什么栈从上往下(高地址->低地址)生长?
- 栈的生长方向:指的是入栈方向,从高地址向低地址生长叫做向下生长,或逆向生长。STM32的栈是向下生长
- 当需要分配新的栈帧时,栈指针将向较低的内存地址方向移动,为新的栈帧分配空间。而当不再需要某个栈帧时,栈指针会向较高的内存地址方向移动,释放该栈帧所占用的内存空间。
操作系统对内存管理的作用
- 内存分配与回收
- 采用虚拟内存进行扩容
- 负责逻辑地址到物理地址的转换
- 实现内存保护与隔离(应用间、内核隔离)
分页管理
定义:将内存分为大小相等的页框、进程也分为页框,OS将进程的页框一一对应放入内存

在进程控制块PCB中存放页表,记录了进程页号和内存块号之间的对应关系

逻辑地址到物理地址的转换
- 依据逻辑地址,整除页面大小得到页号,余数为页内偏移量
- 判断越界
- 通过PCB中保存的页表查询该页存放在哪一块内存(逻辑内存地址)
- 通过逻辑内存地址计算实际物理内存地址

缺页中断
为了使得页表不用常驻内存,将页表分为2级管理,1级页表存储页表索引,2级页表存储内存逻辑地址
当某些页面不在内存中但被访问到时发生缺页中断

虚拟内存
将即将使用的数据装入内存,若内存满了,将不用的数据换入磁盘
第一,虚拟内存可以使得进程对运行内存超过物理内存大小,因为程序运行符合局部性原理,CPU 访问内存会有很明显的重复访问的倾向性,对于那些没有被经常使用到的内存,我们可以把它换出到物理内存之外,比如硬盘上的 swap 区域。
第二,由于每个进程都有自己的页表,所以每个进程的虚拟内存空间就是相互独立的。进程也没有办法访问其他进程的页表,所以这些页表是私有的,这就解决了多进程之间地址冲突的问题。 第三,页表里的页表项中除了物理地址之外,还有一些标记属性的比特,比如控制一个页的读写权限,标记该页是否存在等。在内存访问方面,操作系统提供了更好的安全性。
Nor Flash Nand Flash
NoR Flash中不仅可以存储数据,且可以取指运行(XIR),也就是MCU给出地址,Nor可以直接返回指令交给MCU去执行,这样不用把指令拷贝到RAM里去执行;
NAND Flash仅可用于存储,取值时需要搬运到RAM中
堆和栈的区别
申请方式:stack:系统分配与回收(栈内存分配运算内置于处理器的指令集);heap:程序员申请与释放
存储位置与方向:stack:高地址—》低地址;heap:低地址—》高地址
碎片问题:stack无碎片FIFO;heap存在内外碎片
存放内容:stack:函数返回地址、局部变量的值;heap:用户定义
栈的动态分配主要是malloc函数实现的,由编译器自动释放;堆只有动态分配用new实现,由程序员手动释放
内存碎片
内存碎片分为内碎片与外碎片
外碎片:还没有被分配出去(不属于任何进程),但由于太小了无法分配给申请内存空间的新进程的内存空闲区域。
内碎片:已经被分配出去(能明确指出属于哪个进程)却不能被利用的内存空间;(按固定大小分配给进程)
产生原因:分配较多不连续的空间后,剩余可用空间被孤立
内存对齐
- 平台原因(移植):不是所有的硬件平台都能访问任意地址上的任意数据;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
- 性能原因:为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
如果一个变量的内存地址正好位于它长度的整数倍,他就被称做自然对齐。如果在 32 位的机器下, char 对齐值为1, short 为2, int,float为4,double 为 8
cstruct asd1{
char a;
char b;
short c;
int d;
};//8字节
struct asd2{
char a;
short b;
char c
int d;
};//12字节

规则:按照#pragma pack指定的数值和这个数据成员自身长度中,比较小的那个进行(最后一个char也占用4Byte)
c#pragma pack(4)
struct asd3{
char a;
int b;
short c;
float d;
char e;
};//20字节
#pragma pack()
#pragma pack(1)
struct asd4{
char a;
int b;
short c;
float d;
char e;
};//12字节
#pragma pack()

malloc的底层实现
调用malloc时,去内存空闲链表内寻找可分配的空间,返回首地址指针
以RTT为例:内存管理方法可分为一、内存堆管理(小内存、slab大内存、多内存memheap)与二、内存池管理
一、内存堆管理`
小内存管理:从整块内存中通过链表寻找空闲内存块(逐一向后寻找匹配空间)

slab:将整块内存分为多个不同大小的类别(对号入座)适合于大量的、细小的数据结构的内存申请的情况

memheap:多个地址不连续内存,将其连接起来使用

二、内存池管理
内存池:类似slab,分配大块内存

对比:
| 分配算法 | 优点 | 缺点 | 使用场景 |
|---|---|---|---|
| 内存堆 | 可分配任意大小内存 | 每次均需要查找、容易产生碎片 | 大量细小内存 |
| 内存池 | 分配高效 | 无法分配小内存 | 块设备大量数据 |
虚拟内存
通过地址转换,使得应用程序运行在连续内存上,且与内核隔离
程序的装入、静态链接、动态链接
一、绝对装入(编译时确定绝对地址)
- 再另一台内存不同的电脑上可能无法运行
二、静态重定位(保存相对地址)(读取时转换)
- 编译、链接后存放为逻辑地址,保存的都是相对于0地址的相对值
- 地址空间必须连续且读入内存时,对所有逻辑地址进行运算,转换为物理地址(读入时)
三、动态重定位(保存相对地址)(运行时转换)
- 程序读入内存后,并不直接计算物理地址,实际执行时才进行转换,将逻辑地址转换为物理地址(调用时)


页表
带有权限属性,放在物理内存中的,用来记录虚拟内存页与物理页映射关系的一张表
功能:(虚拟地址与物理地址转换)、(隔离各进程)、(各进程分配连续空间)、(权限管理RW)
| 一级页表 | 多级页表 | 快表 | |
|---|---|---|---|
| 内存访问速度 | 2次(访问页表+访问数据) | 多次(访问一级、二级后访问数据) | 用高速缓存存放常用的页表项 |
| 空间利用率 | 低,虚拟内存越大,页表越大,内存碎片化严重(页表数量限制) | 高,按需分配各级页表 | / |
在1G内存的计算机中能否malloc(1.2G)?
在操作系统上可以,malloc申请的是虚拟内存,而非实际硬件内存。在硬件上不行
brk()与mmap()
在标准C库中,提供了malloc/free函数分配释放内存,这两个函数底层是由brk(C++)sbrk(C),mmap,munmap这些系统调用实现的
进程分配内存的方式有两种系统调用方式:brk与mmap
- brk是将数据段(.data)的最高地址指针_edata往高地址推(高地址释放后低地址才能释放,只适用于小内存分配,碎片多)
- mmap是在进程的虚拟地址空间中(堆和栈中间,称为文件映射区域的地方)找一块空闲的虚拟内存(可以单独释放,碎片少)
相同点:分配的都是虚拟内存,首次访问时发生缺页中断,操作系统再负责分配物理内存,随后建立映射关系



FLEX RAM
TCM : Tightly-Coupled Memory 紧密耦合内存 。ITCM用于指令,DTCM用于数据,特点是跟内核速度一样(400MHz),而片上RAM的速度基本都达不到这个速度(200MHz)。很多时候我们希望将需要实时性的程序和变量分别放在ITCM和DTCM里面执行,本章就是解决这个问题。
- ITCM(指令紧耦合存储器):
- ITCM用于存储指令(程序代码),通常具有较低的访问延迟和较高的带宽,以提供快速和可预测的指令访问。
- ITCM通常与处理器核心直接相连,使得指令可以快速地从该存储区加载,从而加快指令执行速度。
- ITCM的容量相对较小,通常只能存储少量的指令代码。
- DTCM(数据紧耦合存储器):
- DTCM用于存储数据,如变量、栈、堆等,具有较低的读写访问延迟和高带宽。
- DTCM与处理器核心直接相连,以提供快速的数据访问,使得数据可以快速加载和存储,提高数据操作的效率。
- DTCM的容量通常相对较小,只能存储有限量的数据。
- OCRAM(片上随机访问存储器):
- OCRAM是一种通用的片上随机访问存储器,用于存储数据和指令。
- OCRAM的容量通常比ITCM和DTCM更大,可以存储更多的数据和代码。
- OCRAM的访问速度和带宽一般较低,但相对来说会比外部存储器的访问速度快。
三者之间的主要区别在于其设计目标和功能。ITCM主要用于存储指令代码,提供快速指令访问;DTCM主要用于存储数据,提供快速数据访问;OCRAM则是一种通用存储器,可以同时存储指令和数据,容量相对较大,但速度和带宽可能不如ITCM和DTCM。

大家都知道 RAM 是掉电易失的,这种加速的方法如何在量产产品中使用呢?实际上使用以上的方法,MDK 会将特定的函数编译到 ROM 当中,在每次启动的时候都会将 ROM 中指定的函数拷贝到 RAM 放中。
【经验分享】STM32H7时间关键代码在ITCM执行的超简单方法 (stmicroelectronics.cn)
STM32
STM32启动流程
1.依据boot引脚选择启动区域
| 引脚 | 启动方式 | 描述 |
|---|---|---|
| x 0 | 片内Flash | 代码区启动,ICP下载(SWD、JTAG烧录) |
| 0 1 | 系统存储器 | 内置ROM启动,ISP下载(出厂预置代码,UART烧录) |
| 1 1 | SRAM | RAM启动,掉电丢失 |
2.运行bootloader

处理器会将各个寄存器的值初始化为默认值
2.1 硬件设置SP、PC,进入复位中断函数Rest_Hander()
从0x0800 0000读取数据赋值给栈指针SP(MSP),设置为栈顶指针0x2000 0000+RAM_Size
从0x0800 0004读取数据赋值给PC(指向Reset_Handler中断服务函数)
cLDR R0, = SystemInit BLX R0
2.2 设置系统时钟,进入SystemInit()
设置RCC寄存器各位
设置中断向量表偏移地址
c#ifdef VECT_TAB_SRAM
SCB->VTOR = SRAM_BASE | VECT_TAB_OFFSET; /* Vector Table Relocation in Internal SRAM. */
#else
SCB->VTOR = FLASH_BASE | VECT_TAB_OFFSET; /* Vector Table Relocation in Internal FLASH. */
#endif
2.3 软件设置SP,__main入栈(统初始化函数)
cLDR R0,=__main BX R0
2.4 加载data、bss段并初始化_main栈区
拷贝Flash中的数据进入SRAM(哈弗体系结构决定了:数据与代码分开存储)

3 跳转到main()


OTA的情况

在FLASH中添加引导程序后,其与APP程序将各自对应一个中断向量表,假设引导程序占用N+M Byte的FLASH空间。上电后,单片机从复位中断向量表处获取地址,并跳转执行复位中断服务函数,执行完毕后执行主函数,随后执行Bootloader中程序跳转的相关代码跳转至APP,即地址0x08000004+N+M处。进入主函数的步骤与Bootloader函数一致。当运行在主函数时,若有中断请求被响应,此时PC指针本应当指向位于地址0x08000004处的中断向量表,但由于程序预先通过“SCB->VTOR = 0x08000000 | ADDR_OFF;”这一语句,使得中断向量表偏移ADDR_OFF(N+M)地址,因此PC指针会跳转到0x08000004+N+M处所存放的中断向量表处,随后执行本应执行的中断服务函数,在跳出函数后再进入主函数运行。

cvoid iapLoadApp(uint32_t appxAddr)
{
iapfun jumptoapp;
if( 0x20000000 == ( (*(vu32*)appxAddr) & 0x2FFE0000) )//检查appxaddr处存放的数据(栈顶地址0x2000****)是不是在RAM的地址范围内
{
jumptoapp = (iapfun)*(vu32*)(appxAddr + 4);//拷贝APP程序的复位中断函数地址,用户代码区第二个字为程序开始地址(复位地址)(强制跳转到函数地址处执行,函数指针的方式)
MSR_MSP(*(vu32*)appxAddr);//初始化APP堆栈指针(用户代码区的第一个字用于存放栈顶地址),重新分配RAM
jumptoapp();//执行APP的复位中断函数,跳转到APP
}
}
中断的过程
中断初始化
-
设置中断源,让某个外设可以产生中断;
-
设置中断控制器,使能/屏蔽某个外设的中断通道,设置中断优先级等;
-
使能CPU中断总开关
CPU在运行正常的程序
产生中断,比如用户按下了按键 —> 中断控制器 —> CPU
CPU每执行完一条指令(指令有多个时钟周期,取指、译码、执行等)都会检查是否有异常/中断产生
发现有异常/中断产生,开始处理:
-
保存现场(PC、LR、MSP、通用寄存器、FPU压栈)
-
分辨异常/中断,调用对应的异常/中断处理函数
-
恢复现场(PC与出栈)
在执行高优先级中断时如果低优先级中断到来,低优先级中断不会被丢失
当中断发生时,PC设置为一个特定地址,这一地址按优先级排列就称为异常向量表
STM32定时器
系统滴答定时器SysTick(并非外设,CM3内核)
看门狗定时器WatchDog
基本定时器TIM6,TIM7
通用定时器TIM2,TIM3,TIM4,TIM5(输出比较、输入捕获、PWM、单脉冲)
高级定时器TIM1,TIM8(死区控制)
基本定时:预分频、重装载寄存器
PWM:预分频、重装载、比较寄存器
STM32 ADC
STM32F1 ADC,精度为12位,每个ADC最多有16个外部通道,各通道的A/D转换可以单次、连续扫描或间断执行,ADC转换的结果(6-12位)可以左对齐或右对齐储存在16位数据寄存器中。ADC的输入时钟不得超过14MHz,其时钟频率由PCLK2分频产生。
一个ADC的不同通道读取的值在共用的DR寄存器中,进行下一个通道采集前需要将数据取走否则丢失
注入通道:可以在规则通道转换时,强行插入转换
参考电压:3.3V
采集精度与位数:最大测量电压/2^采样位数,例如3.3V / 2^12,采样逐次逼近

精度
实际值和采样值的偏差
分辨率
10cm长的尺子,最小刻度是1mm,分辨率是1mm
由采样位数决定。一个12位的ADC可以将输入电压转换为4096个离散的数值(2^12 = 4096)
STM32 DMA
当外部设备(如硬盘、显卡、网络适配器等)需要与主存储器进行数据交换时,需要通过中央处理器(CPU)作为中介来完成数据传输操作。然而,在大量数据传输的情况下,这样的方式会造成CPU过多地参与数据传输,降低了整体性能。
CPU将外设数据搬运到内存的顺序:
- 外设设置状态寄存器置位
- CPU读取外设数据寄存器到CPU通用寄存器
- CPU将通用寄存器数据写入内存
CPU不介入情况下,将数据在外设与内存中传递

DMA配置:数据宽度(u8 u16 u32),数据量(sizeof),数据地址
循环模式:单轮传输结束后,重置传输计数器,重置传输地址为初始值,再次开始新一轮循环
双缓冲区:一个缓冲区传输完成中断触发后,缓存地址乒乓交换,同时触发回调函数
DMA会节约总线资源吗(不能,他只是节约了CPU)
DMA配置
- 配置DMA控制器:设置DMA通道、数据传输方向(外设到存储器或存储器到外设)、传输模式(单次传输、循环传输等)、数据宽度、传输计数等参数
- 分配内存:如果是外设到存储器的数据传输,需要分配一块足够大小的缓冲区
- 配置DMA通道:将外设和DMA通道连接起来,通常需要配置外设的DMA请求触发方式和DMA通道的优先级等参数。
- 触发DMA传输:启动数据的传输。DMA控制器将自动执行数据的传输,而不需要CPU的干预。
实际应用
- 分析性能瓶颈在哪,是数据频率还是数据量过大
- 数据频率:双DMA BUF
- 数据量:单个大 DMA BUF
STM32中断
定义:正在执行某事件时,被某事件打断,造成任务切换
分类:内核异常、外部中断
嵌套向量中断控制器NVIC:多个优先级中断到来后的处理顺序

处理流程:CPU收到(interrupt request,IRQ)后,通过上下文切换保存当前工作状态,跳转至中断处理函数执行(中断向量表),完成后再出栈执行原有程序
中断和异常
相同点:都是CPU对系统发生的某个事情做出的一种反应
区别:中断由外因引起,异常由CPU本身原因引起

STM32看门狗
定时喂狗,否则触发系统复位
IWDG独立看门狗:采用独立时钟,监视硬件错误
WWDG窗口看门狗:采用系统时钟,监视软件错误(必须在规定时间窗口刷新)(防止跑飞后跳过某些代码段)(进入WWDG中断时,可以保存复位前的数据)
IO口类型
| 分类 | 电平 | 用途 | 备注 |
|---|---|---|---|
| 上拉输入 | 常态高电平(上拉电阻连接VCC) | IO读取 | |
| 下拉输入 | 常态低电平(下拉电阻连接GND) | IO读取 | |
| 推挽输出 | 可以输出高电平和低电平,都有较强驱动能力,IO输出0-接GND, IO输出1 -接VCC | 一般IO输出 | 驱动负载能力强 |
| 开漏输出 | 只能输出低电平,高电平没有驱动能力,需要外部上拉电阻才能真正输出高电平 | 线与功能 | 像IIC中,只要有一个给低电平,那么总线都会被拉低。实现线与功能 |
STM32 主频、Flash、SRAM大小
| 类型 | 主频 | Flash | RAM | 内核 |
|---|---|---|---|---|
| STM32F407IGH6 | 168M | 1024KB | 192KB | M4 |
| STM32L151RET6 | 32M | 512KB | 80KB | M3 |
| STM32F103C8T6 | 72M | 64KB | 20KB | M3 |
| HC32L130E8PA | 48M | 64KB | 8KB | M0+ |
ADC采样原理
逐次逼近转换过程和用天平称物重非常相似。天平称重物过程是,从最重的砝码开始试放,与被称物体进行比较,若物体重于砝码,则该砝码保留,否则移去。再加上第二个次重砝码,由物体的重量是否大于砝码的重量决定第二个砝码是留下还是移去。照此一直加到最小一个砝码为止。将所有留下的砝码重量相加,就得此物体的重量。仿照这一思路,逐次比较型A/D转换器,就是将输入模拟信号与不同的参考电压作多次比较,使转换所得的数字量在数值上逐次逼近输入模拟量对应值。

ARM 汇编
assemblyLDR #从存储器中将一个32位的字数据传送到目的寄存器中。该指令通常用于从存储器中读取32位的字数据到通用寄存器,然后对数据进行处理。 LDR R0,[R1] # 将存储器地址为R1的字数据读入寄存器R0 LDR R0,[R1, #8] // 将存储器地址为R1+8的字数据读入寄存器R0 LDR R1, [R0,#0x12] # 将R0+0x12 地址处的数据读出,保存到R1中(R0 的值不变) LDR R1, [R0,R2] # 将R0+R2 地址的数据计读出,保存到R1中(R0 的值不变)
assemblySTR #从源寄存器中将一个32位的字数据传送到存储器中,使用方式可参考指令LDR STR R0,[R1] # 将R0寄存器的数据写入R1地址的内存 STR R0,[R1, #8] # 将R0中的字数据写入以R1+8为地址的存储器中 STR R0,[R1],#8 # 将R0中的字数据写入以R1为地址的存储器中,并将新地址R1+8写入R1
assemblyMOV R1 #0x10 ; # R1=0x10 将数值放入R1 MOV R0, R1 ; # R0=R1 将寄存器值放入R1 MOVS R3, R1, LSL #2 ; R3=R1<<2,并影响标志位
编译&调试
GCC编译4个过程

- 预处理:展开宏定义,文件嵌套、删除注释
- 编译:转换为汇编(检查语法不检查逻辑)
- 汇编:转换为机器码
- 链接:符号表查找与填充地址,库的链接,将汇编文件中函数的临时0地址进行填充,将每个符号定义与一个内存位置相关联起来
一个程序从开始运行到结束的完整过程(四个过程)
编译预处理、编译、汇编、链接
预处理:(头文件、宏展开、注释去除)gcc -E main.c -o main.i
编译:(语法分析,生成汇编代码)gcc -S main.i -o main.s
汇编:(生成二进制机器码)as main.s -o main.o
链接:(指定路径下寻找库函数)gcc main.o -o main
编译优化选项 -o
| 编译速度 | 代码大小 | 重点 | ||
|---|---|---|---|---|
| o1 | 不变 | 大 | ||
| o2 | 牺牲 | 中 | ||
| o3 | 牺牲 | 中 | 提高速度 | |
| os | 牺牲 | 小 | 降低代码大小 | |
| og | 优化调试体验 |
STM32编译后程序大小与存放位置
1)Code:代码段,存放程序的代码部分;
2)RO-data:(Read Only )只读数据段,存放程序中定义的常量;
3)RW-data:(Read Write)读写数据段,存放初始化为非 0 值的全局变量;
4)ZI-data: (Zero Init) 数据段,存放未初始化的全局变量及初始化为 0 的变量;
cTotal RO Size (Code + RO Data) 53668 ( 52.41kB)
Total RW Size (RW Data + ZI Data) 2728 ( 2.66kB)
Total ROM Size (Code + RO Data + RW Data) 53780 ( 52.52kB)
1)RO Size 包含了 Code 及 RO-data,表示程序占用 Flash 空间的大小;
2)RW Size 包含了 RW-data 及 ZI-data,表示运行时占用的 RAM 的大小;
3)ROM Size 包含了 Code、RO-data 以及 RW-data,表示烧写程序所占用的 Flash 空间的大小;
程序运行之前,需要有文件实体被烧录到 STM32 的 Flash 中,一般是 bin 或者 hex 文件,该被烧录文件称为可执行映像文件。如下图左边部分所示,是可执行映像文件烧录到 STM32 后的内存分布,它包含 RO 段和 RW 段两个部分:其中 RO 段中保存了 Code、RO-data 的数据,RW 段保存了 RW-data 的数据,由于 ZI-data 都是 0,所以未包含在映像文件中。
STM32 在上电启动之后默认从 Flash 启动,启动之后会将 RW 段中的 RW-data(初始化的全局变量)搬运到 RAM 中,但不会搬运 RO 段,即 CPU 的执行代码从 Flash 中读取,另外根据编译器给出的 ZI 地址和大小分配出 ZI 段,并将这块 RAM 区域清零。

编译过程:.c中的变量不分配地址(.o中函数、变量地址为0),链接时依据link file规则分配
链接:将各个.o中的相同段进行合并(.text、.data、.bss),并找到所有符号的引用与定义的位置
交叉编译
定义:在一种环境下,编译另一种环境下运行的代码
是否遇到了系统稳定性问题
用了指针与结构体,为了实现类似C++的特性,存在野指针问题,定位方式:ozone工具debug
依据寄存器PC指针定位到出问题的代码位置,反推函数调用栈,手动查找,并未使用自动化工具分析
控制算法
PID
P:误差*Kp**【弹簧】**
I:误差*Ki后累计**【积分】**
D:当前和之前两次误差的差值*Kd(当过冲时方向相反,为负反馈阻尼)【阻尼】
串级PID
实际使用中由于电流环控制已经由电机实现,因此用户仅实现位置环和速度环


采用串级PID的优势与原因
【1不同工况适应性】对于不同的系统工况,由于电机实际输入是电流(直接控制转速),当电机负载不同时(原有PID参数用于平地行驶,现在爬坡行驶),电机系统模型也不同,采用同一套位置环PID算法较难获得稳定的电机电流输出信号,导致同一套参数的控制效果在其他工况变差。串级PID的引入,使得内环可以让电机速度更快地跟随。
【2系统稳态要求】若仅有位置环PID,达到指定位置时,由于没有对速度的限制,因此可能发生震荡。引入内环后速度也有PID控制器进行反馈,当位置较小时,内环的输入也会变小,从而约束稳态速度减小到0
【3限制速度】对于内环而言,可以采用输出限幅的方式限制转速,从而避免了单位置环PID在偏差较大时电机速度过快。
串级PID的参数整定基本遵循从内到外,先整定内环PID的参数,再整定外环PID的参数
ctypedef struct {
uint8_t mode;
//PID 三参数
fp32 Kp;
fp32 Ki;
fp32 Kd;
fp32 max_out; // 最大输出
fp32 max_iout; // 最大积分输出
fp32 set;
fp32 fdb;
fp32 out;
fp32 Pout;
fp32 Iout;
fp32 Dout;
fp32 Dbuf[3]; // 微分项 0最新 1上一次 2上上次
fp32 error[3]; // 误差项 0最新 1上一次 2上上次
} PID_t;
fp32 PID_Calc(PID_t *pid, fp32 fdb, fp32 set) {
if (pid == NULL) {
return 0.0f;
}
pid->error[2] = pid->error[1];
pid->error[1] = pid->error[0];
pid->set = set;
pid->fdb = fdb;
pid->error[0] = set - fdb;
if (pid->mode == PID_POSITION) {
pid->Pout = pid->Kp * pid->error[0];
pid->Iout += pid->Ki * pid->error[0];
pid->Dbuf[2] = pid->Dbuf[1];
pid->Dbuf[1] = pid->Dbuf[0];
pid->Dbuf[0] = (pid->error[0] - pid->error[1]);
pid->Dout = pid->Kd * pid->Dbuf[0];
LimitMax(pid->Iout, pid->max_iout);
pid->out = pid->Pout + pid->Iout + pid->Dout;
LimitMax(pid->out, pid->max_out);
}
else if (pid->mode == PID_DELTA) {
pid->Pout = pid->Kp * (pid->error[0] - pid->error[1]);
pid->Iout = pid->Ki * pid->error[0];
pid->Dbuf[2] = pid->Dbuf[1];
pid->Dbuf[1] = pid->Dbuf[0];
pid->Dbuf[0] = (pid->error[0] - 2.0f * pid->error[1] + pid->error[2]);
pid->Dout = pid->Kd * pid->Dbuf[0];
pid->out += pid->Pout + pid->Iout + pid->Dout;
LimitMax(pid->out, pid->max_out);
}
return pid->out;
}
KF、EKF、UKF
KF能够使用的前提就是所处理的状态是满足高斯分布的,为了解决这个问题,EKF是寻找一个线性函数来近似这个非线性函数,而UKF就是去找一个与真实分布近似的高斯分布。
KF:最早提出的卡尔曼滤波算法,适用于线性系统,且系统状态和观测误差服从高斯分布。KF通过预测和更新步骤来估计系统的状态,并通过协方差矩阵来描述状态估计的不确定性。然而,KF不能很好地处理非线性系统。
EKF:扩展卡尔曼将非线性系统离散化线性化,并利用线性系统的KF进行状态估差,当非线性度较高时,EKF的估计精度可能下降。
UKF:无迹卡尔曼滤波用来解决非线性系统的问题。UKF通过选取一组称为Sigma点的采样点,保留系统的一阶矩和二阶矩,而不是线性化处理。通过这种方式,UKF能够更好地逼近非线性系统的真实分布,并提供更准确的状态估高斯系统,
卡尔曼滤波
用于过滤高斯噪声(白噪声)


通过k-1时刻的最优估计值预测k时刻的理论值,并根据k时刻的测量值,进行数据融合,得到k时刻的最优估计值(线性离散时不变系统,误差正态分布)
cx(k) = A · x(k-1) + B · u(k) + w(k) // 预测方程:依据k-1时刻的状态,推算k时刻的状态
z(k) = H · x(k) + y(k) // 观测方程
x(k) —— k时刻系统的状态
u(k) —— 控制量
w(k) —— 符合高斯分布的过程噪声,其协方差在下文中为Q
z(k) —— k时刻系统的观测值
y(k) —— 符合高斯分布的测量噪声,其协方差在下文中为R
A、B、H —— 系统参数,多输入多输出时为矩阵,单输入单输出时就是几个常数
在后面滤波器的方程中我们将不会再直接面对两个噪声w(k)和y(k),而是用到他们的协方差Q和R。至此,A、B、H、Q、R这几个参数都由被观测的系统本身和测量过程中的噪声确定了。
c// 时间更新(预测)
x(k|k-1) = A · x(k-1|k-1) + B · u(k) // 系统状态(x)
P(k|k-1) = A · P(k-1|k-1) · AT + Q // 系统协方差(P)
K(k) = P(k|k-1) · HT · (H · P(k|k-1) · HT + R)-1 // 卡尔曼增益K(k)
// 测量更新(校正融合)
x(k|k) = x(k|k-1) + K(k) · (z(k) - H · x(k|k-1)) // 输出值(后验估计)x(k|k)
P(k|k) = (I - K(k) · H) · P(k|k-1) // 更新误差协方差
实际使用:
cx // 观测量初始值
P // 系统协方差
K // 卡尔曼增益,自动计算
Q // 过程噪声的协方差,对初值不敏感,很快收敛
R // 测量噪声的协方差,↑后平滑但是响应变差且收敛慢
while(新观测值)
{
K = P / (P + R); // 增益
x = x + K * (新观测值 - x); // 输出
P = (1 - K) · P + Q; // 更新
}
float Kalman_Filter(float data) {
static float prevData = 0;
static float p = 1; // 估计协方差
static float q = 1; // 过程噪声协方差
static float r = 5; // 观测噪声协方差,控制响应速率
static float kGain = 0;
p += q;
kGain = p / (p + r); //计算卡尔曼增益
data = prevData + (kGain * (data - prevData)); //计算本次滤波估计值
p = (1 - kGain) * p; //更新测量方差
prevData = data;
return data;
}
c//1. 结构体类型定义
typedef struct {
float LastP;//上次估算协方差 初始化值为0.02
float Now_P;//当前估算协方差 初始化值为0
float out;//卡尔曼滤波器输出 初始化值为0
float Kg;//卡尔曼增益 初始化值为0
float Q;//过程噪声协方差 初始化值为0.001
float R;//观测噪声协方差 初始化值为0.543
}KFP;//Kalman Filter parameter
//2. 以高度为例 定义卡尔曼结构体并初始化参数
KFP KFP_height={0.02,0,0,0,0.001,0.543};
/*卡尔曼滤波器
*@param KFP *kfp 卡尔曼结构体参数
* float input 需要滤波的参数的测量值(即传感器的采集值)
*@return 滤波后的参数(最优值)*/
float kalmanFilter(KFP *kfp,float input) {
//预测协方差方程:k时刻系统估算协方差 = k-1时刻的系统协方差 + 过程噪声协方差
kfp->Now_P = kfp->LastP + kfp->Q;
//卡尔曼增益方程:卡尔曼增益 = k时刻系统估算协方差 / (k时刻系统估算协方差 + 观测噪声协方差)
kfp->Kg = kfp->Now_P / (kfp->NOw_P + kfp->R);
//更新最优值方程:k时刻状态变量的最优值 = 状态变量的预测值 + 卡尔曼增益 * (测量值 - 状态变量的预测值)
kfp->out = kfp->out + kfp->Kg * (input -kfp->out);//因为这一次的预测值就是上一次的输出值
//更新协方差方程: 本次的系统协方差付给 kfp->LastP 为下一次运算准备。
kfp->LastP = (1-kfp->Kg) * kfp->Now_P;
return kfp->out;
}
//调用卡尔曼滤波器 实践
float height;
float kalman_height = 0;
kalman_height = kalmanFilter(&KFP_height, height);
C++
面向对象
区别于传统的面向流程,需要抽象出一个类来封装各类方法
- 封装
- 将对象的属性(成员变量)和方法(成员函数)封装到一个类里面,便于管理的同时也提高了代码的复用性。
- 继承
- 最大程度保留类和类之间的关系,提高代码复用性,降低代码维护成本。
- 多态
- 静态多态:编译时确定,函数重载
- 动态多态:运行时确定调用成员函数的时候,会更具调用方法的对象的类型来执行不同的函数。父类指针调用子类对象
继承
public protected peivate
类实例(即类对象)不能直接访问类的 private成员和protected成员,但是能直接访问类的public成员。
无论哪种继承方式,子类都不能直接访问父类的 private成员;但是能直接访问父类的 protected成员和public成员(注意:是子类,而不是类实例),并且能通过父类的protected成员函数和public成员函数间接访问父类的private成员。
对于这三种方式继承的 派生类 来说: 都能访问基类的public, protected 成员;
-
public 的方式继承到派生类,这些成员的权限和在基类里的权限保持一致;
-
protected方式继承到派生类,成员的权限都变为protected;
-
private 方式继承到派生类,成员的权限都变为private;
3.子类通过public方式继承父类,则父类中的public、protected和private属性的成员在 子类 中 依次 是 public、protected和private属性,即通过public继承并不会改变父类原来的数据属性。
4.子类通过protected方式继承父类,则父类中的public、protected和private属性的成员在 子类 中 依次 是 protected、protected和private属性,即通过protected继承原来父类中public属性降级为子类中的protected属性,其余父类属性在子类中不变。
5.子类通过private方式继承父类,则父类中的public、protected和private属性的成员在 子类 中 依次 是 private、private和private属性,即通过private继承原来父类中public属性降级为子类中的private属性,protected属性降级为子类中的private属性,其余父类属性在子类中不变。
注意: 其实父类的原属性并未改变,只是通过 继承关系被继承到子类中的父类成员的个别属性有所变化 ,即只是在子类中父类的个别成员属性降级了,原来父类的成员属性并未变。
友元函数 friend
类的友元函数是定义在类外部,但有权访问类的所有私有(private)成员和保护(protected)成员。尽管友元函数的原型有在类的定义中出现过,但是友元函数并不是成员函数。
c++class Box
{
private:
double width;
public:
friend void printWidth( Box box );
void setWidth( double wid );
};
// 成员函数定义
void Box::setWidth( double wid ) {
width = wid;
}
// 请注意:printWidth() 不是任何类的成员函数
void printWidth( Box box ) {
/* 因为 printWidth() 是 Box 的友元,它可以直接访问该类的任何成员 */
cout << "Width of box : " << box.width <<endl;
}
// 程序的主函数
int main( ) {
Box box;
// 使用成员函数设置宽度
box.setWidth(10.0);
// 使用友元函数输出宽度
printWidth( box );
return 0;
}
static作用,与c的区别
static 作用主要影响着变量或函数的生命周期,作用域,以及存储位置。
一、修饰局部变量:(函数内部、{}内部)
- 变量的存储区域由栈变为静态区。
- 变量的生命周期由局部变为全局。
- 变量的作用域不变。
二、修饰模块内的全局变量:(静态全局变量)
- 变量的存储区域在全局数据区的静态区。
- 变量的作用域由整个程序变为当前文件。(extern声明也不行)(全局变量不暴露)
- 变量的生命周期不变。
三、修饰函数:(当前文件中的函数)
- 函数的作用域由整个程序变为当前文件。(extern声明也不行)(接口不暴露)
四、修饰C++ 成员变量
- 在类外定义与初始化
int A::_count = 0;,类内申明static int _count; - 为该类所有对象所共享
- 访问:类名::变量名
五、修饰C++ 成员函数
- 没有隐藏的
this指针,不能访问非静态成员(变量、 函数) - 不能调用非静态成员函数
- 非静态成员函数可以调用静态成员函数
指针与引用的区别
-
指针:指向一个对象后,对它所指向的变量,间接操作
-
引用:目标变量的别名,直接操作
c++int a = 996;
int *p = &a; // p是指针, &在此是求地址运算
int &r = a; // r是引用, &在此起标识作用
-
引用必须初始化,指针不用
-
引用初始化后不能修改,指针可以改变所指对象
-
指针++为地址,引用++为值
-
sizeof 指针为指针大小,sizeof 引用为数据大小
-
指针转换为引用:*p,随后当参数传入即可
-
引用转换为指针:引用对象&取地址即可
左值引用、右值引用
-
左值是指表达式后可以获取地址的对象。换句话说,左值代表一个可以放在等号左边的值,也可以被修改例如,变量、数组元素和通过引用或指针访问的对象都是左值。 int a = 10; // 其中 a 就是左值
-
右值是指表达式后不可以获取地址的临时对象或字面量。右值代表一个临时值,它只能放在等号右边,不能被修改。例如,数字常量、字符串常量、临时变量、返回的临时对象都属于右值。 int a = 10; // 其中 10 就是右值右值
C++11引入了右值引用(rvalue reference)的概念,允许程序员更方便地对右值进行操作和移动语义,例如移动语义的实现和完美转发。右值引用通过&&表示。
c++int&& r = 42; // 创建一个右引用
移动语义与完美转发 moce fowrard
- std::move是一个函数模板,用于将给定的对象表示为右值(或将其转换为右值用它执行的操作是对传入的对象进行强制转换,使其能够被移动而不是复制。通过使用std::move,我们可以显式地表达出我们要对对象进行移动操作,以便在适当的情况下利用移动语义,提高程序的性能。
- std::forward也是一个函数模板,用于在函数转发(forwarding)时保持参数类型。它与stdmove类似,但是它能够根据传递给它的类型自动进行转发,既可以用于左值引用,也可以用于右值引用。它的主要用途是在实泛型代码时,将函数参数以原始的转发方式传递给其他函数,以保持参数的类型和值的完整性。
总结起来,std::move用于在移动语义中转移对象的所有权,而std::forward则用于完美转发函数参数,保持参数的类型。这两个函数都是为了高效和灵活地处理C++中的对象转移和函数转发而引入的,能够使代码更加简洁和高效。
当使用std::move时,我们可以将一个对象的所有权从一个对象转移到另一个对象。在下面的例子中,通过使用std::move,我们将source的所有权转移到了destination,这样我们就可以高效地移动source的内容而不是逐个复制每个元素。例如:
c++int main() {
std::vector<int> source = {1, 2, 3, 4, 5};
// 使用std::move将source的所有权转移到destination
std::vector<int> destination = std::move(source);
// source现在为空,已经移动到destination
std::cout << "Size of source: " << source.size() << std::endl; // 输出 0 // destination包含原来source元素
std::coutSize of destination: " << destination.size() << std::endl; // 输出
return 0;
}
当使用std::forward时,我们可以在函数转发中保持参数的类型。在这个例子中,我们定义了一个 processValue 函数,它接受一个右值引用参数。然后我们使用 forwardFunction 函数来转发参数,使用 std::forward 将参数完美转发给 processValue 函数。在 main 函数中,我们展示了如何使用 forwardFunction 函数来传递左值和右值,而调用 processValue 函数。通过 std::forward,我们可以在函数转发中保持参数类型的完整性。
c++// 接受参数的函数
void processValue(int&& x) {
std::cout << "Processing rvalue: " << x << std::endl;
}
// 使用std::forward转template<typename T>
void forwardFunction(T&& arg) {
processValue(std::forward<T>(arg));
}
int main() {
int value = 42;
// 传递左值,调用processValue函数
forwardFunction(value);
// 传递右值,调用processValue函数
forwardFunction(std::move(value));
return 0;
}
std::forward相比于简单地将参数传递给另一个函数而言,可以提高代码的效率,主要体现在以下几个方面:
- 避免多余的拷贝:当参数是左值(lvalue)时,使用std::forward可以将参数作为左值引用传递给下一层函数,避免产生额外的拷贝操作。如果直接传递参数,会导致参数被当作右值(rvalue)来处理,从而触发拷贝构造函数。
- 精确匹配重载函数:有时我们在一个函数中需要对传递的参数进行重载函数的调用,而这些重载函数可能接受不同的参数类型(比如一个接受左值引用,一个接受右值引用)。使用std::forward可以精确匹配原始传入参数的类型,从而调用正确的重载函数。
- 消除重载冗余:std::forward使用引用折叠规则,从而避免引入额外的重载函数,以减少代码的冗余。通过std::forward,可以将参数的左值引用和右值引用统一起来,消除了传递参数时的冗余重载处理。
总而言之,std::forward提供了一种高效的方式来将参数按照原始的值类别和修饰符转发给下一层函数,避免了多余的拷贝操作,精确匹配重载函数,并消除了重载冗余,从而提高了代码的效率。
模板类
c++// XX.h
template <typename T>
class MyTemplateClass {
private;
T data;
public:
MyTemplateClass(T value) : data(value) {} // 构造函数
void printData() {
std::cout << "Data: " << data << std::endl; // 模板类方法
}
};
// XX.cpp
MyTemplateClass<int> obj1(10); // 实例化为处理int类型的对象
MyTemplateClass<double> obj2(3.14); // 实例化为处理double类型的对象
obj1.printData(); //: Data: 10
obj2.printData(); // 输出: Data: 3.14
为什么模板类写在.h中,不在.cpp中
模版是在编译的时候实例化的,实例化需要知道模版参数的具体类型,如果把模版的声明和定义分离编译的话,那么cpp文件中的模版实现不知道T的类型,无法实例化。都写到头文件中就解决了
在C++中,模板类通常需要在头文件(.h)中进行定义和实现,而不是分离到.cpp文件中。这是由C++的编译模型和模板实例化的特性决定的。
模板类是在使用时根据实际的模板参数进行实例化的,编译器需要在编译阶段生成模板类的实例化代码。因此,编译器需要在编译阶段能够访问模板类的完整定义和现,以便为每个模板参数生成对应的实例化代码。
如果将模板和实现分离,那编译阶段只能看到模板类,无法生成实例化的代码。这将导致链接阶段找不到所需的实例化代码,进而导致链接错误。
new和malloc的区别
| new | malloc | |
|---|---|---|
| 语法 | int *p = new int(0)或int *p = new int | int *p = (int*)malloc(sizeof(int)) |
| 初始化 | 可以初始化 | 无 |
| 函数与运算法 | 操作符,返回指定类型的地址,不需类型转换 | 函数,返回void * |
| 失败返回值 | 抛出异常bad_alloc | 返回NULL |
| 构造析构调用 | 创建对象时自动调用 | 无 |
可以用malloc给一个类对象分配内存吗
malloc分配内存不会调用构造函数
new与delete实现
实际调用malloc 与 free,但区别如下:
- 申请失败后,new返回值为异常,bad_malloc,malloc返回NULL
- 对于内置数据类型一致,对于类,执行构造函数与析构函数
new 实际调用brk()与mmap()系统调用
深浅拷贝
- 浅拷贝就是增加了一个指向相同堆区的指针,这将导致在析构的时候会重复释放。默认的拷贝构造和运算符重载都是浅拷贝。
- 深拷贝是在拷贝的时候将内容申请内存,重新拷贝一份,放到内存中,指针指向这个新拷贝的部分,这样就不会出现析构的时候重复释放的问题了。
重载和重写
重载:在同一个类中,方法相同,参数数量与类型不同(静态多态性),例:构造函数,函数名相同,参数同(返回值无法判读)
重写:在父类与子类中,方法与参数都相同(动态多态性),子类对象调用该方法时,父类方法被屏蔽
虚函数作用及底层实现原理
- 实现多态性
- 公有继承(基类定义虚函数,派生类可以重写)
- 动态联编(父类指针指向子类对象时,调用子类方法)(类似函数重载(静态),重写为动态的)
c++//Base Class
class Student {
private:
int m_id;
// protected:
string m_name;
int m_gender;
public:
Student();
Student(string name, int gender, int id);
virtual ~Student(); //申明virtual方法的基类中的析构函数必须为虚函数,否则在释放指针指向的派生类对象时,将调用基类的析构函数造成错误
virtual void Show_Info();
};
//Derived Class
class Student_Zju : public Student{
private:
int m_ser_num;
public:
Student_Zju();
Student_Zju(string name, int gender, int id, int ser_num);
virtual ~Student_Zju();
virtual void Show_Info();
};
实现机制:为每个类对象添加一个隐藏成员,保存了一个指向函数(虚函数)地址数组的指针,称为虚表指针(虚函数表)
-
如果派生类重写了基类的虚方法,该派生类虚函数表将保存重写的虚函数的地址,而不是基类的虚函数地址。
-
如果基类中的虚方法没有在派生类中重写,那么派生类将继承基类中的虚方法,而且派生类中虚函数表将保存基类中未被重写的虚函数的地址。注意,如果派生类中定义了新的虚方法,则该虚函数的地址也将被添加到派生类虚函数表中。
含有纯虚函数的类是否可以实例化
不可以,需要被派生类继承后才行
在基类中不能对虚函数给出具体的有意义的实现,就可以把它声明为纯虚函数,它的实现留给该基类的派生类去做。
c++class VirtualClass{
public:
virtual void fun1() = 0; // 纯虚函数
virtual ~VirtualClass();
};
class ClassA : public VirtualClass{
public:
virtual void fun1() { // 虚函数
printf("VirtualClass\n");
};
virtual ~VirtualClass();
};
int main(){
//编译报错,这个非法的
VirtualClass * virtualClass = new VirtualClass();//error: cannot allocate an object of abstract type 'VirtualClass'
VirtualClass * classA = new ClassA();
classA->fun1();
return 0;
}
构造函数是否可以是虚函数,析构函数为什么建议是虚函数
构造函数不可以是虚函数,如果构造函数时虚函数,那么调用构造函数就需要去找vptr,而此时vptr还没有初始化
析构函数需要是虚函数,当父类指针指向子类对象时,释放子类对象时,若父类析构非虚,会调用父类析构,子类相较于父类多出的方法不会被析构
c++BaseClass* pObj = new SubClass();
delete pObj;
- 若析构函数是虚函数(即加上virtual关键词),delete时基类和子类都会被释放
- 若析构函数不是虚函数(即不加virtual关键词),delete时只释放基类,不释放子类,会造成内存泄漏问题
虚函数表与内存模型
假如一个类有虚函数,当我们构建这个类的实例时,将会额外分配一个指向该类虚函数表的指针,当我们用父类的指针来操作一个子类的时候,这个指向虚函数表的指针就派上用场了,它指明了此时应该使用哪个虚函数表
C++虚函数表的位置——从内存的角度 - 知乎 (zhihu.com)
- 每个类,只要含有虚函数,new出来的对象就包含一个虚函数指针,指向这个类的虚函数表(这个虚函数表一个类用一张)
- 子类继承父类,会形成一个新的虚函数表,但是虚函数的实际地址还是用的父类的,如果子类重写了某个虚函数,那么子类的虚函数表中存放的就是重写的虚函数的地址
- 不同类之间可以通过强制转型调用其他类的虚函数
如何判断一个方法来自父类还是子类
方法一:可以在父类或子类的相应方法print()一个标记 方法二:dynamic_cast
c++class Tfather {
public:
virtual void f() { cout << "father's f()" << endl; }
};
class Tson : public Tfather {
public:
void f() { cout << "son's f()" << endl; }
int data; // 我是子类独有成员
};
int main() {
Tfather father;
Tson son;
son.data = 123;
Tfather *pf;
Tson *ps;
/* 上行转换:没有问题,多态有效 */
ps = &son;
pf = dynamic_cast<Tfather *>(ps);
pf->f();
/* 下行转换(pf实际指向子类对象):没有问题 */
pf = &son;
ps = dynamic_cast<Tson *>(pf);
ps->f();
cout << ps->data << endl; // 访问子类独有成员有效
/* 下行转换(pf实际指向父类对象):含有不安全操作,dynamic_cast发挥作用返回NULL */
pf = &father;
ps = dynamic_cast<Tson *>(pf);
assert(ps != NULL); // 违背断言,阻止以下不安全操作
ps->f();
cout << ps->data << endl; // 不安全操作,对象实例根本没有data成员
/* 下行转换(pf实际指向父类对象):含有不安全操作,static_cast无视 */
pf = &father;
ps = static_cast<Tson *>(pf);
assert(ps != NULL);
ps->f();
cout << ps->data << endl; // 不安全操作,对象实例根本没有data成员
system("pause");
}
菱形继承
D类的对象不确定调用哪个父类的方法

c++class Animal{
private:
int weight;
public:
virtual int getWeight() {
return this->weight; // 共用虚函数
}
};
class Tiger : public Animal{};
class Lion : public Animal{};
class Liger : public Tiger, public Lion{}; // 如此定义存在问题,不确定调用哪个getWeight()
int main()
{
Liger lg;
lg.getWeight(); // 非法
lg.Lion::getWeight(); // 合法
}
c++// 解决方案
class Animal{
private:
int weight;
public:
virtual int getWeight() {
return this->weight;
}
};
class Tiger : virtual public Animal{}; // 加入virtual虚继承
class Lion : virtual public Animal{};
class Liger : public Tiger, public Lion{};
int main()
{
Liger lg;
lg.getWeight();
}
拷贝构造函数与赋值构造函数
区别:赋值时对象是否已经存在
C++每一个类提供默认的拷贝构造函数,但成员变量涉及指针时,浅拷贝带来问题,需要自定义深拷贝
拷贝构造函数调用的情况:
c++// 拷贝构造
Complex c2(c1); //拷贝构造函数初始化
Complex c2 = c1; //首次创建对象是初始化,不是赋值语句
void Func(Class a) {balabala} //调用函数时,Class将实参拷贝构造为形参
// 对象作为函数参数
void func(Class class);
// 函数返回值为一个非引用型对象
return A_class;
// 使用一个对象初始化另一个对象
Clsss a = b; // (a不存在,需要构造)
// 有参构造函数
Class c(a); //调用拷贝构造函数
重载的赋值运算符调用情况:
c++// 赋值构造
Complex c1, c2; //默认构造函数
c1 = c2 ; //重载的赋值运算符,已经存在对象,不是拷贝构造
// 运算符重载
A& operator = (const A& other) {}
// 赋值
Class a;
a = b; // 对象存在,调用赋值
c++#include <iostream>
class MyClass {
private:
int privateMember;
public:
// 默认构造函数
MyClass() : privateMember(0) {
std::cout << "Default constructor called." << std::endl;
}
// 拷贝构造函数
MyClass(const MyClass& other) : privateMember(other.privateMember) {
std::cout << "Copy constructor called." << std::endl;
}
// 赋值构造函数
MyClass& operator=(const MyClass& other) {
std::cout << "Assignment operator called." << std::endl;
if (this == &other) {
return *this;
}
privateMember = other.privateMember;
return *this;
}
// 获取私有成员的值
int getPrivateMember() const {
return privateMember;
}
// 设置私有成员的值
void setPrivateMember(int value) {
privateMember = value;
}
};
int main() {
MyClass obj1; // 调用默认构造函数
obj1.setPrivateMember(42);
MyClass obj2 = obj1; // 调用拷贝构造函数
MyClass obj3;
obj3 = obj1; // 调用赋值构造函数
std::cout << "Value of obj1's private member: " << obj1.getPrivateMember() << std::endl;
std::cout << "Value of obj2's private member: " << obj2.getPrivateMember() << std::endl;
std::cout << "Value of obj3's private member: " << obj3.getPrivateMember() << std::endl;
return 0;
}
C++如何实现只在栈上实例化对象
(24条消息) 如何限制对象只能建立在堆上或者栈上_舒夜无痕的博客-CSDN博客
c++class A { // 只在堆heap上建立对象,调用create()函数在堆上创建类A对象,调用destory()函数释放内存
protected:
A(){}
~A(){}
public:
static A* create() {
return new A();
}
void destory() {
delete this;
}
};
只有使用new运算符,对象才会建立在堆上,因此,只要禁用new运算符就可以实现类对象只能建立在栈上。将operator new()设为私有即可。
c++class A { // 只在栈stack上建立对象
private:
void* operator new(size_t t){} // 注意函数的第一个参数和返回值都是固定的
void operator delete(void* ptr){} // 重载了new就需要重载delete
public:
A(){}
~A(){}
};
如何避免内存泄漏,用过什么智能指针,智能指针的实现原理
C++没有内存回收机制,每次程序员new出来的对象需要手动delete,流程复杂时可能会漏掉delete,导致内存泄漏
智能指针:
- shared_ptr(引用计数,新增++,过期--,0释放)
- unique_ptr(独占式,不允许复制拷贝)(线程安全)
- weak_ptr(解决循环引用计数问题)(循环引用计数:两个智能指针互相指向对方,造成内存泄漏。需要weak_ptr,将其中的一个指针设置为weak_ptr。)(因为weak_ptr没有共享资源,它的构造函数不会引起智能指针引用计数的变化)
c++#include <iostream>
#include <memory> // 头文件
using namespace std;
class A {
public:
A(int count) { // 构造
_nCount = count;
}
~A(){} // 析构
void Print() {
cout<<"count:"<<_nCount<<endl; // 公有方法
}
private:
int _nCount; // 私有成员变量
};
int main() {
shared_ptr<A> p(new A(10)); // 初始化,堆上新建一个类,p为智能指针
p->Print(); // 调用
return 0;
}
c++#include <memory>
shared_ptr<int> p = make_shared<int> (100); // 指针指向一块存放100的地址,推荐使用
shared_ptr<int> p {new int(100)}; // 第二种创建方式
c++#include <memory>
unique_ptr<int> p = make_unique<int>(100); // 独占指针
unique_ptr<int> p1(p.release()); // 将p的指向及所有权转移到p1
unique_ptr<int> p1 = std::move(p); // 同样的
shared_ptr多线程安全问题
- 同一个shared_ptr被多个线程“读”是安全的;
- 同一个shared_ptr被多个线程“写”是不安全的;
- 共享引用计数的不同的shared_ptr被多个线程”写“ 是安全的;
引用计数是线程安全的,但在多个线程中对其进行修改不安全
shared_ptr是线程安全的吗?-腾讯云开发者社区-腾讯云 (tencent.com)
当我们谈论shared_ptr的线程安全性时,我们在谈论什么? - 掘金 (juejin.cn)
内存泄漏检测
内存泄漏(Memory Leak)是指程序中已动态分配的堆内存由于某种原因程序未释放或无法释放,造成系统内存的浪费,导致程序运行速度减慢甚至系统崩溃等严重后果
避免内存泄露的方法
- 有良好的编码习惯,动态开辟内存空间,及时释放内存
- 采用智能指针来避免内存泄露
- 采用静态分析技术、源代码插装技术等进行检测
同步I/O与异步I/O
同步I/O是指程序在进行输入/输出操作时会阻塞当前线程,直到操作完成才继续执行后续代码(死等)
异步I/O是指程序在进行输入/输出操作时不会阻塞当前线程,而是继续执行后续代码,并通过回调或者轮询等机制来获取I/O操作的结果(让出权限等待唤醒)
- 同步I/O简单直观,代码编写相对容易,但会阻塞线程造成资源浪费。
- 异步I/O能够充分利用系统资源,提高并发性能,但需要处理回调和事件驱动等复杂性。
STL常见容器及其内部实现的数据结构
| 名称 | 描述 | 存储结构 | 方法 |
|---|---|---|---|
| vector | 动态分配的数组 | 顺序,array | v.capacity(); //容器容量--v.size(); //容器大小--v.at(int idx); //用法和[]运算符相同--v.push_back(); //尾部插入--v.pop_back(); //尾部删除--v.front(); //获取头部元素--v.back(); //获取尾部元素--v.begin(); //头元素的迭代器--v.end(); //尾部元素的迭代器--v.insert(pos,elem); //pos是vector的插入元素的位置--v.insert(pos, n, elem) //在位置pos上插入n个元素elem--v.insert(pos, begin, end);--v.erase(pos); //移除pos位置上的元素,返回下一个数据的位置--v.erase(begin, end); //移除[begin, end)区间的数据,返回下一个元素的位置--reverse(pos1, pos2); //将vector中的pos1~pos2的元素逆序存储 |
| list | 双向链表 | 离散 | (1) 元素访问:lt.front();--lt.back();--lt.begin();--lt.end();--(2) 添加元素:--lt.push_back();--lt.push_front();--lt.insert(pos, elem);--lt.insert(pos, n , elem);--lt.insert(pos, begin, end);--lt.pop_back();--lt.pop_front();--lt.erase(begin, end);--lt.erase(elem);--(3)sort()函数、merge()函数、splice()函数:--sort()函数就是对list中的元素进行排序;--merge()函数的功能是:将两个容器合并,合并成功后会按从小到大的顺序排列;--比如:lt1.merge(lt2); lt1容器中的元素全都合并到容器lt2中。--splice()函数的功能是:可以指定合并位置,但是不能自动排序! |
| stack | 栈 | 用list或deque实现 | |
| quque | 队列 | 用list或deque实现 | |
| deque | 双端队列 | 分段连续(多个vector连续) | (1) 元素访问:d[i];--d.at[i];--d.front();--d.back();--d.begin();--d.end();--添加元素:d.push_back();--d.push_front();--d.insert(pos,elem); //pos是vector的插入元素的位置--d.insert(pos, n, elem) //在位置pos上插入n个元素elem--d.insert(pos, begin, end);--删除元素:d.pop_back();--d.pop_front();--d.erase(pos); //移除pos位置上的元素,返回下一个数据的位置--d.erase(begin, end); //移除[begin, end)区间的数据,返回下一个元素的位置 |
| priority_queue | 优先级队列 | vector | |
| set | 集合(有序不重复) | 红黑树(弱平衡二叉搜索树,二分查找法搜索高效) | s.size(); //元素的数目--s.max_size(); //可容纳的最大元素的数量--s.empty(); //判断容器是否为空--s.find(elem); //返回值是迭代器类型--s.count(elem); //elem的个数,要么是1,要么是0,multiset可以大于一begin 返回一个指向集合中第一个元素的迭代器。--cbegin 返回指向集合中第一个元素的const迭代器。--end 返回指向末尾的迭代器。--cend 返回指向末尾的常量迭代器。--rbegin 返回指向末尾的反向迭代器。--rend 返回指向起点的反向迭代器。--crbegin 返回指向末尾的常量反向迭代器。--crend 返回指向起点的常量反向迭代器。--s.insert(elem);--s.insert(pos, elem);--s.insert(begin, end);--s.erase(pos);--s.erase(begin,end);--s.erase(elem);--s.clear();//清除a中所有元素; |
| multiset | 集合(有序可重复) | 红黑树 | |
| unordered_set | 集合(无序不重复) | hash | |
| map | 键值对(有序不重复) | 红黑树 | |
| multimap | 键值对(有序可重复) | 红黑树 | |
| unordered_map | 键值对(无序不重复) | hash | |
| hash_map | 哈希表,类似map,速度更快 | hash |
deque底层数据结构

红黑树
非严格的平衡搜索二叉树,有自动排序的功能
sort()
仅支持随机访问的数据结构进行快速排序,如vector、deque、array
c++bool func(int a, int b) {
return a > b;
}
sort(vec.begin(), vec.end(), func); // 升序排列
partial_sort()
对部分元素进行升序/降序排列,利用大顶堆/小顶堆实现,堆空间为n
c++bool func(int a, int b) {
return a > b;
}
int n = 4; // 需要排序的数量
partial_sort(vec.begin(), vec.begin() + n, vec.end(), func); // 仅排序其中的n个元素
is_sorted()
c++bool func(int a, int b) {
return a > b;
}
bool result = is_sorted(vec.begin(), vec.end(), func()) // 返回值为bool,是否按照func定义的顺序排序
is_sorted_until()
c++bool func(int a, int b) {
return a > b;
}
auto it = is_sorted(vec.begin(), vec.end(), func()) // 返回值:指向序列中第一个破坏 comp 排序规则的元素迭代器
find()
c++vector<int> vec{ 10,20,30,40,50 };
auto it = find(vec.begin(), vec.end(), 30); // 起始、终止迭代器、查找的值
if (it != myvector.end())
cout << "查找成功:" << *it;
else
cout << "查找失败";
return 0;
find_if()
按照自定义谓词查找
c++bool mycomp(int i) {
return ((i % 2) == 1);
}
vector<int> myvector{ 4,2,3,1,5 };
auto it = find_if(myvector.begin(), myvector.end(), mycomp());
使用vector如何避免频繁的内存重新分配
内存分配的过程:
- 分配新的内存块,在大部分实现中,vector和string的容量每次以2为因数增长。也就是说,当容器必须扩展时,它们的容量每次翻倍。
- 把所有元素从容器的旧内存拷贝到它的新内存。
- 销毁旧内存中的对象。
- 回收旧内存。
解决方案:
- 预分配内存:在创建 vector 对象时,可以使用 reserve() 方法来预分配内存空间,以避免频繁扩容。
- 合理选择初始容量:在创建 vector 对象时,可以根据数据量的大小估算出合理的初始容量,这样可以尽可能减少扩容的次数。
- 优化算法:尽可能使用时间复杂度低的算法,避免数据量过大时的性能问题。
vector resize()与reserve()
- resize(Container::size_type n)强制把容器改为容纳n个元素。调用resize之后,size将会返回n。如果n小于当前大小,容器尾部的元素会被销毁。如果n大于当前大小,新默认构造的元素会添加到容器尾部。如果n大于当前容量,在元素加入之前会发生重新分配。
- reserve(Container::size_type n)强制容器把它的容量改为至少n,提供的n不小于当前大小。这一般强迫进行一次重新分配,因为容量需要增加。(如果n小于当前容量,vector忽略它,这个调用什么都不做,string可能把它的容量减少为size()和n中大的数,但string的大小没有改变。)
vector的扩容系数为什么是1.5或2
面试题:C++vector的动态扩容,为何是1.5倍或者是2倍_vector扩容_森明帮大于黑虎帮的博客-CSDN博客
扩容原理为:申请新空间,拷贝元素,释放旧空间,理想的分配方案是在第N次扩容时如果能复用之前N-1次释放的空间就太好了,如果按照2倍方式扩容,第i次扩容空间大小如下:
可以看到,每次扩容时,前面释放的空间都不能使用。比如:第4次扩容时,前2次空间已经释放,第3次空间还没有释放(开辟新空间、拷贝元素、释放旧空间),即前面释放的空间只有1 + 2 = 3,假设第3次空间已经释放才只有1+2+4=7,而第四次需要8个空间,因此无法使用之前已释放的空间,但是按照小于2倍方式扩容,多次扩容之后就可以复用之前释放的空间了。
Linux中:内存heap区域被事先分配为2^n大小,以2的倍数扩容可以方便地进行分配
Win中:内存被free的区域会被系统立即合并,以1.5被分配可以使用被释放的内存
迭代器
作用:对于不同的数据结构,通过迭代器均可实现遍历,多态
[注意]:迭代器只能前进不能后退
迭代器失效的情况
迭代器失效分三种情况考虑,也是分三种数据结构考虑,分别为数组型,链表型,树型数据结构。
**数组型数据结构:**该数据结构的元素是分配在连续的内存中,insert和erase操作,都会使得删除点和插入点之后的元素挪位置,所以,插入点和删除掉之后的迭代器全部失效,也就是说insert(*iter)(或erase(*iter)),然后在iter++,是没有意义的。解决方法:erase(*iter)的返回值是下一个有效迭代器的值。 iter =cont.erase(iter);
**链表型数据结构:**对于list型的数据结构,使用了不连续分配的内存,删除运算使指向删除位置的迭代器失效,但是不会失效其他迭代器.解决办法两种,erase(*iter)会返回下一个有效迭代器的值,或者erase(iter++).
树形数据结构: 使用红黑树来存储数据,插入不会使得任何迭代器失效;删除运算使指向删除位置的迭代器失效,但是不会失效其他迭代器.erase迭代器只是被删元素的迭代器失效,但是返回值为void,所以要采用erase(iter++)的方式删除迭代器。
注意:经过erase(iter)之后的迭代器完全失效,该迭代器iter不能参与任何运算,包括iter++,*ite
内联函数inline
作用:将函数入栈出栈的调用开销减少,(将函数展开为代码)
优势:
- 对于简单函数而言加快运行速度,省去了参数压栈、栈帧开辟与回收,结果返回等
- 相当于有类型检查的宏定义,且可以调试
缺陷:
- 以膨胀代码为代价
- 不能包含循环、递归等复杂操作
- 是否内联,程序员不可控。内联函数只是对编译器的建议,是否对函数内联,决定权在于编译器。
- 可能影响代码的执行效率,因为内联函数的本质是把函数体直接嵌入到调用处,这样会导致代码的大小增加,从而可能导致缓存命中率下降,影响执行效率。
哈希表
查表,要枚举的话时间复杂度是O(n),但如果使用哈希表的话, 只需要O(1)就可以做到。我们只需要初始化把这所学校里学生的名字都存在哈希表里,在查询的时候通过索引直接就可以知道这位同学在不在这所学校里了。
哈希碰撞:

解决方法:
链表法(tableSize=dataSize)

线性探测法(tableSize>=dataSize)将冲突的元素放到下一个空位中

哈希操作
- 查找:当使用键进行查找时,哈希表会使用键的哈希值来确定其在哈希表中的位置,并进一步比较键的值来判断是否匹配。如果键相同,那么可以通过哈希值直接找到对应的位置,并返回存储在该位置上的值。
- 插入:在向哈希表中插入键值对时,哈希表首先会计算键的哈希值,并根据哈希值找到对应的位置。然后,它会检查该位置上是否已经存在相同的键。如果存在相同的键,则可以选择更新现有的值,或者根据具体的实现策略来处理冲突。
- 删除:当从哈希表中删除一个键值对时,哈希表会使用键的哈希值来定位该键所在的位置。如果在该位置上找到了匹配的键,就将其从哈希表中删除。
当两个对象映射到同一个哈希地址时,是否说明这两个对象相同
当两个对象产生哈希冲突时,它们被映射到了相同的哈希地址上,但并不能确定它们的内容是否相同。两个不同的对象完全可以具有相同的哈希值,因为哈希值只是一个对输入对象进行计算得出的结果。
要确定两个对象是否相同,通常需要使用其他方法,如比较它们的内容、引用或标识符等。哈希地址相同并不代表对象相同,只能说它们在哈希函数中产生了冲突。
哈希表如何解决键值冲突
哈希表(散列表)根据(Key value)直接进行访问的数据结构。映射函数叫做散列函数,存放记录的数组叫做散列表。
哈希值是通过哈希函数计算出来的,通过哈希函数计算出来的哈希值相同,就是哈希冲突,不能完全避免
解决方案:
- 开放定址法:发现冲突后寻找下一个空闲散列表位置
- 再哈希法:利用不同的哈希函数再次计算哈希值(多轮)
- 链地址法:每个哈希表节点都有一个next指针,多个哈希表节点可以用next指针构成一个单向链表,被分配到同一个索引上的多个节点可以用这个单向链表连接起来,因而查找、插入和删除主要在同义词链中进行。
- 公共溢出区法:冲突放入溢出表
CMake是如何包含文件目录的
cmaketarget_include_directories(test PRIVATE ${YOUR_DIRECTORY}) #添加要包含的目录 set(SOURCES file.cpp file2.cpp ${YOUR_DIRECTORY}/file1.h ${YOUR_DIRECTORY}/file2.h) #将头文件添加到当前目标的源文件列表中 add_executable(test ${SOURCES})
extern c
C++不能直接调用C编译器编译的代码
在C++中可能调用C的代码段用关键字进行包裹,例子如下
extern "C" 修饰一段 C++ 代码,让编译器以处理 C 语言代码的方式来处理修饰的 C++ 代码。
c++// FUNC.h通用模板
#ifndef __INCvxWorksh /*防止该头文件被重复引用*/
#define __INCvxWorksh
#ifdef __cplusplus //告诉编译器,这部分代码按C语言的格式进行编译,而不是C++的
extern "C"{
#endif
/* C语言实现的部分函数申明 */
/* C语言实现的部分函数申明 */
#ifdef __cplusplus
}
#endif
#endif /*end of __INCvxWorksh*/
extern "C"的主要作用就是为了能够正确实现C++代码调用其他C语言代码。加上extern "C"后,会指示编译器这部分代码按C语言(而不是C++)的方式进行编译。由于C++支持函数重载,因此编译器编译函数的过程中会将函数的参数类型也加到编译后的代码中,而不仅仅是函数名;而C语言并不支持函数重载,因此编译C语言代码的函数时不会带上函数的参数类型,一般只包括函数名。
c++//moduleA.h
int fun(int, int);
//moduleA.C
#include"moduleA"
int fun(int a, int b)
{
return a+b;
}
//moduleB.h
#ifdef __cplusplus //而这一部分就是告诉编译器,如果定义了__cplusplus(即如果是cpp文件,
extern "C"{ //因为cpp文件默认定义了该宏),则采用C语言方式进行编译
#include"moduleA.h"
#endif
… //其他代码
#ifdef __cplusplus
}
#endif
//moduleB.cpp
#include"moduleB.h"
int main()
{
cout<<fun(2,3)<<endl;
}
总结
通常在C++ 中,假如需要使用C语言中的库文件的话,可以使用extern "C"去包含c编写的头文件
设计模式
单例模式
在整个系统生命周期内,保证一个类只能产生一个实例,确保该类的唯一性。成员函数均为static
工厂模式
抽象出一个工厂,工厂有不同的产线继承自工厂类,对于产品抽象出产品类
字符串string char*互转
c// char[] 转 char*
char ch[]="abcdef";
char *s = ch;
// char* 转 char[]
char *s="abcdef";
char ch[100];
strcpy(ch,s);
// string 转 char[]
string str= "abcdef";
char ch[20];
int i;
for( i=0;i<=str.length();i++){
ch[i] = str[i];
if(i==str.length()) c[i] = '\0';
}
// char[] 转 string
string str;
char ch[20] = "abcdef";
str = ch;
// string 转 char*
string str = "abcdef";
const char* p = (char*)str.data(); // data()仅返回字符串内容,而不含有结束符’\0’
string str=“abcdef”;
const char *p = str.c_str();
//使用char * p=(char*)str.c_str()效果相同
string str=“abcdef”+ '\0';
char *p= new char[str.length()+1];
str.copy(p,str.length(),0); // 要想指针指向内容及地址不改变,使用该方式
// char* 转 string
string str;
char *p = "abcdef";
str = p;
char *p = "abcdef";
string str;
str.assign(p,strlen(p)); // 要想指针指向内容及地址不改变,使用该方式
C++11、C++14、C++17、C++20 新特性
- C++11 新特新 - static_assert 编译时断言 - 新增加类型 long long ,unsigned long long,char16_t,char32_t,原始字符串 - auto - decltype - 委托构造函数 - constexpr - 模板别名 - alignas - alignof - 原子操作库 - nullptr - 显示转换运算符 - 继承构造函数 - 变参数模板 - 列表初始化 - 右值引用 - Lambda 表达式 - override、final - unique_ptr、shared_ptr - initializer_list - array、unordered_map、unordered_set - 线程支持库
- C++14 新特新 - 二进制字面量 - 泛型 Lambda 表达式 - 带初始化/泛化的 Lambda 捕获 - 变量模板 - [[deprecated]]属性 - std::make_unique - std::shared_timed_mutex、std::shared_lock - std::quoted - std::integer_sequence - std::exchange
- C++17 新特新 - 构造函数模板推导 - 结构化绑定 - 内联变量 - 折叠表达式 - 字符串转换 - std::shared_mutex
- C++20 新特新 - 允许 Lambda 捕获 [=, this] - 三路比较运算符 - char8_t - 立即函数(consteval) - 协程 - constinit
C++11中的atomic
C++11引入了一组原子类型(Atomic Types),用于解决多线程环境下的并发访问问题。原子类型保证了对变量的读写操作是原子的,即不会发生数据竞争。
c++#include <iostream>
#include <atomic>
#include <thread>
std::atomic<int> counter(0);
void incrementCounter() {
for (int i = 0; i < 1000; ++i) {
counter.fetch_add(1, std::memory_order_relaxed);
}
}
int main() {
std::thread t1(incrementCounter);
std::thread t2(incrementCounter);
t1.join();
t2.join();
std::cout << "Counter value: " << counter << std::endl;
return 0;
}
C++多线程
pthread_create
创建子线程,并注册回调函数
pthread_join
在主线程中调用,等待子线程执行完毕后,释放子线程资源,再执行join后的代码
pthread_detach
主线程在调用pthread_detach(子线程ID) 与pthread_exit(NULL)后,不用等待Join才可释放子线程资源,在子线程结束运行前,主线程可以执行其他功能,子线程运行结束后资源由OS而非主线程释放

pthread_cancel
在主线程中杀死子线程(通过系统调用,延迟杀死线程)
pthread_equal
比较两个线程ID是否一致
父子进程fork()
当一个进程调用 fork 函数生成另一个进程,原进程就称为父进程,新生成的进程则称为子进程。
c++#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(int argc, char * argv[])
{
int pid;
/* fork another process */
pid = fork();
if (pid < 0)
{
/* error occurred */
fprintf(stderr,"Fork Failed!");
exit(-1);
}
else if (pid == 0)
{
/* child process */
printf("This is Child Process!\n");
}
else
{
/* parent process */
printf("This is Parent Process!\n");
/* parent will wait for the child to complete*/
wait(NULL);
printf("Child Complete!\n");
}
}

可以建立一个新进程,把当前的进程分为父进程和子进程,新进程称为子进程,而原进程称为父进程。fork调用一次,返回两次,这两个返回分别带回它们各自的返回值,其中在父进程中的返回值是子进程的PID,而子进程中的返回值则返回 0。因此,可以通过返回值来判定该进程是父进程还是子进程。
孤儿进程
父进程释放,子进程还在,内核接管,没有危害
僵尸进程
子进程退出,父进程不知道,此时子进程还占用着资源
在 Linux 环境中,我们是通过 fork 函数来创建子进程的。创建完毕之后,父子进程独立运行,父进程无法预知子进程什么时候结束。通常情况下,子进程退出后,父进程会使用 wait 或 waitpid 函数进行回收子进程的资源,并获得子进程的终止状态。但是,如果父进程先于子进程结束,则子进程成为孤儿进程。孤儿进程将被 init 进程(进程号为1)领养,并由 init 进程对孤儿进程完成状态收集工作。而如果子进程先于父进程退出,同时父进程太忙了,无瑕回收子进程的资源,子进程残留资源(PCB)存放于内核中,变成僵尸(Zombie)进程
解决方案:
- 父进程在子进程退出时调用wait()/waitpid()函数来回收子进程的资源
- fork一个孙子进程,然后将子进程变为一个孤儿进程可以避免僵尸进程的产生
- 杀死这个僵尸进程的父进程。那么该僵尸进程就会被守护进程给领养。从而守护进程,会对这个僵尸进程的内核区资源进行回收。
僵尸进程其实已经就是退出的进程,因此无法再利用kill命令杀死僵尸进程。僵尸进程的罪魁祸首是父进程没有回收它的资源,那我们可以想办法它其它进程去回收僵尸进程的资源,这个进程就是 init 进程。因此,我们可以直接杀死父进程,init 进程就会很善良地把那些僵尸进程领养过来,并合理的回收它们的资源,那些僵尸进程就得到了妥善的处理了。
例如,如果 PID 5878 是一个僵尸进程,它的父进程是 PID 4809,那么要杀死僵尸进程 (5878),您可以结束父进程 (4809):
$ sudo kill -9 4809 #4809 is the parent, not the zombie
守护进程
前台进程是在终端中运行的命令,那么该终端就为进程的控制终端,一旦这个终端关闭,这个进程也随着消失
- 而守护进程(Daemon),也就是我们平时说的后台进程,是运行在后台的一种特殊进程,不受终端控制,它不需要终端的交互
- 守护进程是一种特殊的后台进程,它通常在系统启动时自动启动,并在系统运行过程中一直运行,执行一些系统级别的任务,如监控系统资源、处理网络请求等。守护进程通常不与用户交互,也不需要终端,而是在后台默默地运行,直到系统关闭或者被显式地停止。
协程
C++20新增
协程不受操作系统调度,切换方便,轻量级
- 依赖关系:线程是由操作系统内核进行调度管理的,并且每个线程通常拥有自己的独立堆栈和上下文。而协程则是由程序员在代码中显式地定义和管理的,没有操作系统参与调度。协程依赖于某种运行时环境或者特定的库来实现调度和切换。
- 并发性能:线程属于操作系统层面的并发机制,它可以充分利用多核处理器的计算能力。每个线程都需要一定的系统资源来进行管理,因此创建大量线程可能会导致资源消耗过大。相比之下,协程是轻量级的,可以在单个线程中运行大量的协程,节省了线程切换的开销。
- 切换机制:在线程之间进行切换时,需要进行上下文的保存和恢复,这是由操作系统内核负责完成的,并且通常涉及到用户态和内核态之间的切换。而协程的切换是在用户态完成的,切换开销更小。协程通过手动选择合适的切换点,在不同的协程之间进行切换,使得程序可以在合适的时机保存和恢复中间状态。
- 同步方式:线程通常通过共享内存或者消息传递来进行通信和同步。而协程则通常通过显式的调度和消息传递机制来实现数据共享和同步。协程之间的切换是协作性的,需要各个协程自行决定何时让出执行权。
总的来说,线程更加底层和系统级别,可以充分利用多核处理器的并行计算能力,但线程数量受限于系统资源,并且线程切换开销较大。而协程是一种高级抽象,更适合处理大量的轻型任务,并且协程之间的切换开销较小。但协程需要依赖特定的运行时环境或库的支持,无法直接利用多核处理器的并行计算能力。
网络编程
OSI网络模型
| 层级 | 名称 | 作用 | 协议 | 关键词 |
|---|---|---|---|---|
| 7 | 应用层 | 各类网络服务 | HTTP、FTP | |
| 6 | 表示层 | 数据编码、格式转换、加密 | LPP、NBSSP | |
| 5 | 会话层 | 维护会话 | SSL、TLS、DAP、LDAP | |
| 4 | 传输层 | 建立主机端到端的连接(应用间的通信) | TCP、UDP | 端口号、TCP、UDP |
| 3 | 网络层 | 路由选择,控制数据包在设备间的转发(主机间通信) | **IP、ICMP、路由器、**RIP、IGMP、OSPF | IP地址、路由器、ping通 |
| 2 | 数据链路层 | 将比特流封装成数据帧(数据帧、网卡间通信) | ARP、网卡、交换机、PPTP、L2TP、ATMP | MAC地址、网卡 |
| 1 | 物理层 | 定义电平、传输介质、物理接口 | 光纤、集线器、中继器等物理器件 |
TCP&UDP
- TCP 提供面向连接的可靠传输,UDP 提供面向无连接的不可靠传输。
- UDP 在很多实时性要求高的场景有很好的表现,而TCP在要求数据准确、对速度没有硬性要求的场景有很好的表现。

UDP
- 面向无连接(不需要三次握手和四次挥手)
- 尽最大努力交付、面向报文(每次收发都是一整个报文段)
- 没有拥塞控制不可靠(只管发不管过程和结果)
- 支持一对一、一对多、多对一和多对多的通信方式、首部开销很小(8字节)
优点是快,没有TCP各种机制,少了很多首部信息和重复确认的过程,节省了大量的网络资源。
缺点是不可靠不稳定,只管数据的发送不管过程和结果,网络不好的时候很容易造成数据丢失。
语音通话、视频会议等要求源主机要以恒定的速率发送数据报,允许网络不好的时候丢失一些数据,但不允许太大的延迟,UDP很适合这种要求。
TCP
- 面向连接(需要三次握手四次挥手)
- 单播(只能端对端的连接)
- 可靠交付(有大量的机制保护TCP连接数据的可靠性)
- 全双工通讯(允许双方同时发送信息,也是四次挥手的原由)
- 面向字节流(不保留数据报边界的情况下以字节流的方式进行传输,这也是长连接的由来。)
- 头部开销大(最少20字节)
优点是可靠、稳定,有确认、窗口、重传、拥塞控制机制,在数据传完之后,还会断开连接用来节约系统资源。
缺点是慢,效率低,占用系统资源高,在传递数据之前要先建立连接,这会消耗时间,而且在数据传递时,确认机制、重传机制、拥塞机制等都会消耗大量的时间,而且要在每台设备上维护所有的传输连接。
在要求数据准确、对速度没有硬性要求的场景有很好的表现,比如在FTP(文件传输)、HTTP/HTTPS(超文本传输),TCP很适合这种要求。
TCP三次握手四次挥手
tcp的三次挥手的作用是保证 通信双方都能够正常的收发信息;三次握手的发生阶段是在客户端连接服务器的connect阶段开始的
- 公安局:你好!陈某,听得到吗?(一次会话)
- 陈某:听到了,王哥,你能听到吗 (二次会话)
- 公安局:听到了,你过来自首吧 (开始会话)(三次会话)

-
第一次握手 客户端发起SYN包
-
第二次握手 服务器收到后,回复SYN+ACK包
-
第三次握手 客户端收到后,回复ACK包

有人可能会很疑惑为什么要进行第三次握手? 主要原因:防止已经失效的连接请求报文突然又传送到了服务器,从而客户端建立1个连接,服务器建立2个连接
- 第一次握手: 客户端向服务器端发送报文 证明客户端的发送能力正常
- 第二次握手:服务器端接收到报文并向客户端发送报文 证明服务器端的接收能力、发送能力正常
- 第三次握手:客户端向服务器发送报文 证明客户端的接收能力正常
如果采用两次握手会出现以下情况: 客户端向服务器端发送的请求报文由于网络等原因滞留,未能发送到服务器端,此时连接请求报文失效,客户端会再次向服务器端发送请求报文,之后与服务器端建立连接,当连接释放后,由于网络通畅了,第一次客户端发送的请求报文又突然到达了服务器端,这条请求报文本该失效了,但此时服务器端误认为客户端又发送了一次连接请求,两次握手建立好连接,此时客户端忽略服务器端发来的确认,也不发送数据,造成不必要的错误和网络资源的浪费。
四次挥手
作用是将服务器和客户端的连接安全的断开,四次挥手是发生在客户端或者服务器断开连接的时候
- 张三:好的,那我先走了
- 李四:好的,那你走吧
- 李四:那我也走了?
- 张三:好的,你走吧

- 第一次挥手 客户端发出FIN包
- 第二次挥手 服务器收到后,发出ACK包,(此时双方还可以继续传输数据)
- 第三次挥手 服务器发送FIN包
- 第四次挥手 客户端收到后回复ACK包,进入超时等待状态,服务器端接收到确认报文后,会立即关闭断开

为什么客户端要等待2MSL? 主要原因是为了保证客户端发送那个的第一个ACK报文能到到服务器,因为这个ACK报文可能丢失,并且2MSL是任何报文在网络上存在的最长时间,超过这个时间报文将被丢弃,这样新的连接中不会出现旧连接的请求报文。当服务端一段时间后无法收到最后一个ACK包时,会重发FIN包,再次进入流程
浏览器从输入 URL 开始到页面显示内容,中间发生了什么?
- DNS解析域名,获取ip端口
- 建立tcp链接
- http发送请求
- 服务器处理请求
- 服务器端返回数据
- 浏览器解析html
- 浏览器布局渲染
TCP可靠传输机理
TCP是通过序列号、检验和、确认应答信号、重发机制、连接管理、窗口控制、流量控制、拥塞控制一起保证TCP传输的可靠性的。
TCP(传输控制协议)通过以下机制来保证可靠传输:
- 应答机制:发送方在发送数据包后,会等待接收方的确认应答。如果发送方没有收到确认应答,就会重新发送数据包,直到收到确认为止。
- 序列号和确认号:TCP将每个数据包都赋予一个唯一的序列号,接收方收到数据包后会发送一个确认应答,并指定下一个期望接收的数据的序列号。发送方根据接收方的确认号知道哪些数据已经成功发送并被接收。
- 滑动窗口:发送方将数据分割为多个小的数据段,并使用滑动窗口的机制进行发送。接收方通过确认号告诉发送方数据被接收,发送方可以根据确认号调整滑动窗口的大小和发送速率。
- 重传机制:如果发送方在一定时间内未收到确认应答,就会认为数据包丢失,并进行重传。接收方在收到重复的数据包时会丢弃重复的数据,确保只有一个副本被交付给上层应用。
- 流量控制:TCP使用滑动窗口的机制来控制发送方发送数据的速率,避免发送过多的数据导致接收方无法及时处理或丢失数据。
- 拥塞控制:TCP根据网络的拥塞程度动态调整发送方的发送速率,避免过多的数据流入网络导致拥塞。TCP使用拥塞窗口大小和重传超时时间等参数来判断网络的拥塞情况,并采取相应的措施,如减小发送速率或等待较长时间进行重传。
TCP 粘包
TCP基于字节流,无法判断发送方报文段边界
造成粘包的因素有很多,有可能是发送方造成的,也有可能是接收方造成的。比如接收方在接收缓存中读取数据不及时,在下一个数据包到达之前没有读取上一个,可能也会造成读取到超过一个数据包的情况。多个数据包被连续存储于连续的缓存中,在对数据包进行读取时由于无法确定发生方的发送边界
发送端可能堆积了两次数据,每次100字节一共在发送缓存堆积了200字节的数据,而接收方在接收缓存中一次读取120字节的数据,这时候接收端读取的数据中就包括了下一个报文段的头部,造成了粘包。
解决粘包的方法:
- 发送方关闭Nagle算法,使用TCP_NODELAY选项关闭Nagle功能
- 发送定长的数据包。每个数据包的长度一样,接收方可以很容易区分数据包的边界
- 数据包末尾加上\r\n标记,模仿FTP协议,但问题在于如果数据正文中也含有\r\n,则会误判为消息的边界
- 数据包头部加上数据包的长度。数据包头部定长4字节,可以存储数据包的整体长度
Linux
Linux嵌入式驱动开发的流程
- 了解硬件设备及其规范:首先要对目标硬件设备进行研究,包括芯片型号、外设接口、寄存器规范等。同时,对于设备的功能和特性也需要有基本的了解。
- 编写设备树(Device Tree)描述文件:Linux内核使用设备树来描述硬件设备的信息。需要编写设备树描述文件,以便内核能够识别和配置硬件设备。
- 编写驱动程序源码:根据设备的规格和需求,编写对应的驱动程序源码。通常需要涉及到底层寄存器的读写、中断处理、设备初始化和资源分配等操作。
- 将驱动程序源码添加到内核源码树:将驱动程序源码添加到Linux内核源码树,并在内核配置选项中选择该驱动模块进行编译。
- 构建并刷写内核镜像:完成驱动程序源码的添加和内核配置后,进行内核的构建。通过编译得到的内核镜像可以刷写到目标嵌入式设备上。
- 调试和测试:将构建好的内核镜像刷写到目标设备,并进行调试和测试。检查设备与驱动之间的通信,确保驱动程序能够正确地初始化设备并提供所需的功能。
- 优化和性能测试:根据实际使用情况对驱动程序进行优化,并进行性能测试。通过性能测试来评估驱动程序的性能,并进行必要的调整和优化。
Linux内核的组成
五部分:进程管理、内存管理、进程间通信、虚拟文件系统、网络接口
1.进程管理与调度:

2.内存管理:Linux内存管理对于每个进程完成从虚拟内存到物理内存的转换

3.虚拟文件系统:隐藏硬件的细节,采用vfs_read,vfs_write等接口

4.网络接口:分为网络协议和网络驱动程序

5.进程间通信:信号量、共享内存、消息队列、管道等,实现资源互斥、同步
系统调用read() write(),内核具体做了哪些事情
用户空间read()-->内核空间sys_read()-->scull_fops.read-->scull_read();
过程分为两个部分:用户空间的处理和内核空间的处理。
在用户空间中通过 0x80 中断的方式将控制权交给内核处理,
内核接管后,经过6个层次的处理最后将请求交给磁盘,由磁盘完成最终的数据拷贝操作。在这个过程中,调用了一系列的内核函数。
系统调用与普通函数调用的区别
| 类别 | 系统调用 | 函数调用 |
|---|---|---|
| 简介 | 调用内核的服务 | 调用函数库中的一个程序 |
| 涉及对象 | 程序与内核 | 用户与程序 |
| 运行空间 | 内核地址空间 | 用户地址空间 |
| 开销 | 上下文切换,开销大 | 小 |
Bootloader内核 、根文件的关系
启动顺序:bootloader->linuxkernel->rootfile
u-boot:初始化硬件,将内核装载入RAM,设置SP与PC,准备启动内核
kernel:(底层驱动向内核注册,上层应用向内核调用)启动并挂载rootfile(存放了文件、库、命令)
rootfile:业务涉及的文件系统
Bootloader启动过程
上电后运行的第一个程序:bootloader(u-boot)(universal bootloader)
- 典型嵌入式系统的部署:uboot程序(类似BIOS)部署在Flash(能作为启动设备的NorFlash)上、OS部署在FLash(嵌入式系统中用Flash代替了硬盘)上、内存在掉电时无作用,CPU在掉电时不工作。
- 启动过程:嵌入式系统上电后先执行uboot、然后uboot负责初始化DDR,初始化Flash,然后将OS从Flash中读取到DDR中,然后启动OS(OS启动后uboot就无用了) 总结:嵌入式系统和PC机的启动过程几乎没有两样,只是BIOS成了uboot,硬盘成了Flash。
Stage1(汇编实现,依赖cpu体系结构初始化)
进行硬件的初始化(watchdog,ram初始化) 为Stage2加载代码准备RAM空间 复制Stage2阶段代码到RAM空间 设置好栈 跳转到第二阶段代码的入口点
Stage2(c语言实现,具有好的可读性和移植性)
初始化该阶段所用到的硬件设备。 检测系统内存映射。 将uImage ,Rootfs,dtb文件从flash读取到RAM内存中。 设置内核启动参数。(如通过寄存器传递设备树文件的内存地址)
Linux启动流程
- 引导加载程序(Bootloader)启动:U-Boot 被加载到内存中执行。 U-Boot 提供了一个命令行界面,用户可以在这个界面上进行配置和操作。
- 加载内核和备树文件:通过 U-Boot 的命令,加载 Linux 内核kernel)和设备树(device tree)文件到内存中4. 启动 Linux 内核:U-Boot控制权交给 Linux 内核,内核开始执行。内核会初始化系统硬设置页表、启动调度器等。
- 启动 init 进:在内核初始化完成后,内核会执行 init 进程,init 进程是用户空间的第一个进程。 init 进程负责启动其他系统服务,并根据配置加载所需的模块。
- 用户空间初始化:init 进程会根据配置启动用户空间的各个进程和服务,完成系统的初始化。
设备树
Linux设备树(Device Tree)是一种描述硬件设备和设备间关系的数据结构,用于在嵌入式系统中配置和管理硬件。它是一种与平台无关的机制,它将硬件设备的相关信息以一种可移植的格式储存在一个或多个设备树文件中。
设备树文件是以一种层级结构的形式描述硬件设备及其属性。它包含了设备的类型、寄存器地址、中断、时钟等信息,以及设备间的关系和依赖关系。通过解析设备树文件,内核可以获取设备的配置信息,并正确地初始化和管理硬件设备。
Linux 命令
搜索:
grep *.c
grep -n "linux" test.txt // 查找文件中的关键字并显示行号
搜索文件
find /home/user/dir -type f -name "*.c"
-type f表示只搜索文件,而不包括目录
查看文件内容:
cat:将原文显示
进程:
ps:查看进程
$ ps -ax PID TTY STAT TIME COMMAND 1 ? Ss 0:01 /usr/lib/systemd/systemd rhgb --switched-root --sys 2 ? S 0:00 [kthreadd] 3 ? I< 0:00 [rcu_gp] 4 ? I< 0:00 [rcu_par_gp]
pstree:查看父子进程关系
$ pstree -psn systemd(1)─┬─systemd-journal(952) ├─systemd-udevd(963) ├─systemd-oomd(1137) ├─systemd-resolve(1138) ├─systemd-userdbd(1139)─┬─systemd-userwor(12707) │ ├─systemd-userwor(12714) │ └─systemd-userwor(12715) ├─auditd(1140)───{auditd}(1141) ├─dbus-broker-lau(1164)───dbus-broker(1165) ├─avahi-daemon(1166)───avahi-daemon(1196) ├─bluetoothd(1167)
内存占用:
free –h:系统相关RAM使用情况(物理内存、交换内存)
top:查看系统CPU、进程、内存使用情况
磁盘占用:
df -h:查看磁盘占用
关机、重启、挂起、节电:
shutdown -h now
shutdown -h +10 // 延时10min
shutdown -h 19:30
sudo reboot
sudo pm-suspend
sudo pm-powersave
手动释放内存的方法
采用TOP命令查看内存张后,采用/proc/sys/vm/drop_caches来释放内存
[root@ipa]# echo 0~3 > /proc/sys/vm/drop_caches
drop_caches的值可以是0-3之间的数字,代表不同的含义: 0:不释放(系统默认值) 1:释放页缓存 2:释放dentries和inodes 3:释放所有缓存
文件系统

查看程序依赖的动态链接库
c++#include <stdio.h>
#include <iostream>
#include <string>
using namespace std;
int main ()
{
cout << "test" << endl;
return 0;
}
# g++ -o demo main.cpp
# ldd demo // 查看依赖的动态链接库文件
linux-vdso.so.1 => (0x00007fffcd1ff000)
libstdc++.so.6 => /usr/lib64/libstdc++.so.6 (0x00007f4d02f69000)
libm.so.6 => /lib64/libm.so.6 (0x00000036c1e00000)
libgcc_s.so.1 => /lib64/libgcc_s.so.1 (0x00000036c7e00000)
libc.so.6 => /lib64/libc.so.6 (0x00000036c1200000)
/lib64/ld-linux-x86-64.so.2 (0x00000036c0e00000)
如果程序引入动态链接库,但没有使用,一样会被链接,且影响启动速度,下面的例子
c++# g++ -o demo -lz -lm -lrt main.cpp // 加入用不到的.so
# ldd demo
linux-vdso.so.1 => (0x00007fff0f7fc000)
libz.so.1 => /lib64/libz.so.1 (0x00000036c2600000)
librt.so.1 => /lib64/librt.so.1 (0x00000036c2200000)
libstdc++.so.6 => /usr/lib64/libstdc++.so.6 (0x00007ff6ab70d000)
libm.so.6 => /lib64/libm.so.6 (0x00000036c1e00000)
libgcc_s.so.1 => /lib64/libgcc_s.so.1 (0x00000036c7e00000)
libc.so.6 => /lib64/libc.so.6 (0x00000036c1200000)
libpthread.so.0 => /lib64/libpthread.so.0 (0x00000036c1a00000)
/lib64/ld-linux-x86-64.so.2 (0x00000036c0e00000)
# ldd -u demo // 查看没有用到的.so
Unused direct dependencies:
/lib64/libz.so.1
/lib64/librt.so.1
/lib64/libm.so.6
/lib64/libgcc_s.so.1
软连接、硬连接
系统中只有一份数据,若一个用户修改,其他用户可以同步感知
硬链接:通过索引节点来进行链接。磁盘中的文件具有的索引编号(Inode)(允许一个文件拥有多个有效路径名)

- 以文件副本的形式存在。但不占用实际空间。
- 不允许给目录创建硬链接。
- 硬链接只有在同一个文件系统中才能创建。
- 删除其中一个硬链接文件并不影响其他有相同 inode 号的文件。
- 不同用户看来文件名可以不同
软连接:(符号连接,快捷方式)软链接就是一个普通文件,存放另一文件的路径
- 软链接是存放另一个文件的路径的形式存在。
- 可以跨文件系统
- 可以对一个不存在的文件名进行链接,硬链接必须要有源文件。
- 可以对目录进行链接。
shell[oracle@Linux]$ touch f1 #创建一个测试文件f1 原有文件
[oracle@Linux]$ ln f1 f2 #创建f1的一个硬连接文件f2 ln 源地址 目标地址
[oracle@Linux]$ ln -s f1 f3 #创建f1的一个符号连接文件f3 ln -s 源地址 目标地址
[oracle@Linux]$ ls -li # -i参数显示文件的inode节点信息
total 0
9797648 -rw-r--r-- 2 oracle oinstall 0 Apr 21 08:11 f1
9797648 -rw-r--r-- 2 oracle oinstall 0 Apr 21 08:11 f2
9797649 lrwxrwxrwx 1 oracle oinstall 2 Apr 21 08:11 f3 -> f1
#硬连接文件 f2 与原文件 f1 的 inode 节点相同,均为 9797648,然而符号连接文件的 inode 节点不同。
shell[oracle@Linux]$ echo "I am f1 file" >>f1
[oracle@Linux]$ cat f1
I am f1 file
[oracle@Linux]$ cat f2
I am f1 file
[oracle@Linux]$ cat f3
I am f1 file
[oracle@Linux]$ rm -f f1
[oracle@Linux]$ cat f2
I am f1 file
[oracle@Linux]$ cat f3
cat: f3: No such file or directory
#当删除原始文件 f1 后,硬连接 f2 不受影响,但是符号连接 f3 文件无效

Linux权限
文件角色有3种:
- 文件拥有者 :谁创建这文件谁就是拥有者;
- 文件所属组 :所有用户都要隶属于某一个组,哪怕只有一个人;
- 其他人 :除了拥有者之外的人都是other。
更改拥有者 : 需要 sudo 提升到管理员身份才能修改
**更改所属组 :**sudo chgrp yz func.c
权限数字定义
-
rwx = 4 + 2 + 1 = 7
-
rw = 4 + 2 = 6
-
rx = 4 +1 = 5
即
-
若要同时设置 rwx (可读写运行) 权限则将该权限位 设置 为 4 + 2 + 1 = 7
-
若要同时设置 rw- (可读写不可运行)权限则将该权限位 设置 为 4 + 2 = 6
-
若要同时设置 r-x (可读可运行不可写)权限则将该权限位 设置 为 4 +1 = 5
设备驱动

逻辑设备表

记录了逻辑设备名称与物理设备名称的对应关系以及驱动程序入口地址
字符设备、块设备、网络设备

socket
用户建立一个socket,指明网络协议、端口号等,在内核中开辟一个空间,返回句柄fd
用户将数据包用write系统调用传给内核,内核调用网卡驱动发送出去
对端主机反向处理数据,应用采用read系统调用读取

grep
shellgrep "^a" a.txt ## 查找以a开头的行
grep "^a.*r$" a.txt ## 同时查找以a开头同时以r结尾的行
grep "^a.*h.*r$" a.txt ## 同时查找以a开头,包含字符h,并以r结尾的行
grep "^a\|e$" a.txt ## 提取以a开头,或者以e结尾的行
\ 反义字符:如"\"\""表示匹配""
[ - ] 匹配一个范围,[0-9a-zA-Z]匹配所有数字和字母
* 所有字符,长度可为0
+ 前面的字符出现了一次或者多次
^ #匹配行的开始 如:'^grep'匹配所有以grep开头的行。
$ #匹配行的结束 如:'grep$'匹配所有以grep结尾的行。
. #匹配一个非换行符的字符 如:'gr.p'匹配gr后接一个任意字符,然后是p。
* #匹配零个或多个先前字符 如:'*grep'匹配所有一个或多个空格后紧跟grep的行。
.* #一起用代表任意字符。
[] #匹配一个指定范围内的字符,如'[Gg]rep'匹配Grep和grep。
[^] #匹配一个不在指定范围内的字符,如:'[^A-FH-Z]rep'匹配不包含A-R和T-Z的一个字母开头,紧跟rep的行。
\(..\) #标记匹配字符,如'\(love\)',love被标记为1。
\< #到匹配正则表达式的行开始,如:'\<grep'匹配包含以grep开头的单词的行。
\> #到匹配正则表达式的行结束,如'grep\>'匹配包含以grep结尾的单词的行。
x\{m\} #重复字符x,m次,如:'0\{5\}'匹配包含5个o的行。
x\{m,\} #重复字符x,至少m次,如:'o\{5,\}'匹配至少有5个o的行。
x\{m,n\} #重复字符x,至少m次,不多于n次,如:'o\{5,10\}'匹配5--10个o的行。
\w #匹配文字和数字字符,也就是[A-Za-z0-9],如:'G\w*p'匹配以G后跟零个或多个文字或数字字符,然后是p。
\W #\w的反置形式,匹配一个或多个非单词字符,如点号句号等。
\b #单词锁定符,如: '\bgrep\b'只匹配grep。
文件大小写转换
shellcat file | tr a-z A-Z > newfile #将文件内容转换为大写
LInux是否支持浮点运算
Linux kernel默认不支持浮点计算。因为浮点相关寄存器(浮点计算上下文)在系统调用(进程切换)的过程中不会被保存,出于进程切换效率的考虑
Linux的7种文件类型
-
普通文件类型
Linux中最多的一种文件类型, 包括 纯文本文件;二进制文件;数据格式的文件;各种压缩文件。第一个属性为 [-]
-
目录文件
就是目录, 能用 cd 命令进入的。第一个属性为 [d]
-
块设备文件
块设备文件 : 硬盘。例如一号硬盘的代码是 /dev/hda1等文件。第一个属性为 [b]
-
字符设备
即串行端口的接口设备,例如键盘、鼠标等等。第一个属性为 [c]
-
套接字文件
这类文件通常用在网络数据连接。可以启动一个程序来监听客户端的要求,客户端就可以通过套接字来进行数据通信。第一个属性为 [s],最常在 /var/run目录中看到这种文件类型
-
管道文件
FIFO也是一种特殊的文件类型,它主要的目的是,解决多个程序同时存取一个文件所造成的错误。第一个属性为 [p]
-
链接文件
类似Windows下面的快捷方式。第一个属性为 [l]
Cortex-M能否运行Linux
不能,其不存在硬件的MMU(内存管理单元)(将硬件物理地址映射到虚拟地址并做检查)
STM32MP1(Cortex-A7)可运行Linux
shell脚本语法与命令
shell#!/bin/bash
echo "Hello World !" # 打印输出
your_name="runoob.com" # 定义变量
本文作者:zzw
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 License 许可协议。转载请注明出处!